

前言
終於來到了我們 【ChatGPT GPTs 開發入門】系列的尾聲,今天我們將介紹如何為您的 GPTs 架設一個資料庫。類似於我們之前分享的 OAuth 導入,這次我們選擇了一個容易上手的線上資料庫服務 - Astra Db。
在選擇要介紹的方案時,我們進行了廣泛的調查研究並慎重考慮。從一開始的 Vercel Postgres,到考慮是否選用像 Zapier Table、AirTable 這類專門提供 Serverless 整合的方案。
最終,我們決定從最適合初學者的 NoSql 雲端資料庫開始,讓大家輕鬆開啟資料存儲服務的旅程。我們相信,一旦大家完成第一個完整的 GPTs Action 服務,既能認證使用者又能儲存資料,便會激發出更多學習的興趣。屆時,將有更多機會深入了解其他高效進行線上操作(新增/查詢/更新/刪除)的傳統關聯式資料庫。
MongoDb 與 AstraDb 的比較
當我開始選擇 NoSql 資料庫時,MongoDb 是我的首選,主要是因為它在台灣已有多年的普及。但鑑於我曾經不適當地使用 NoSql 來代替更適合的傳統關聯式資料庫,這段經驗讓我很謹慎考慮是否應該將 NoSql 資料庫作為初學者的入門選擇。在這個探索過程中,我偶然發現了 Apache 提供的另一種 NoSql 解決方案 — Cassandra,從而引領我認識到了 Astra Db。
在 MongoDb 和 AstraDb 之間的抉擇過程中,我經歷了一番思考和掙扎。作為一名對 MongoDb 比較熟悉的使用者,我也探索了許多選擇 AstraDb(即 Cassandra 解決方案)的理由。以下是我認為選擇 Astra Db 的幾個關鍵因素:
導入的速度與操作便利性 這點尤其重要,我希望幫助非專業 IT 人員能夠迅速地導入自己的雲端資料庫系統。最初我嘗試使用 Mongo Cloud,但它的複雜設計讓人望而卻步。相比之下,我在 Astra Db 上進行的首次資料庫設置過程,簡直讓 Mongo Db 相形見絀。
向量資料庫的支援 這一點對我來說也是一個亮點,特別是考慮到我們未來打算開發的 ChatGPT 相關應用,會大量涉及向量資料庫。
資料讀寫效率、可用性以及查詢的便利性 這些都是我在技術選型時重視的因素。從以下的技術比較文章來看,Cassandra 似乎是 Rational Db 和 NoSql Db 的完美結合,具備了傳統 Rational 資料庫和 NoSql 資料庫的優點,這是一個值得深入研究的領域。
了解 Cassandra 與 MongoDB 之間的差異 – AWS (amazon.com)
基於以上理由,我最終決定引導大家使用 AstraDb 來實現自己的 GPTs 應用。
設定流程
現在讓我們進入本文的核心部分,即整個設定流程。整體來說,流程會包括以下幾個步驟:
設定 Astra Db
部署 Vercel 專案
調整 Vercel 主機的基本設定
安裝並設定 PluginLab 插件以及 ChatGPT GTPs Action 等
後半部分,即 PluginLab 和 ChatGPT GPTs Action 的設定,因為在我們的上一篇文章中已有詳細介紹,本篇文章將主要集中於前面提到的資料庫設定以及 Vercel 專案的部署部分。對於後半部分的詳細內容,請參考我們之前的文章(相關連結將在後面提供)。
詳細步驟
設定 Astra Db
首先,前往 Astra Db 的網站:DataStax 官網。完成帳號註冊和登入後,您將進入 Astra Db 的控制面板,如下所示:
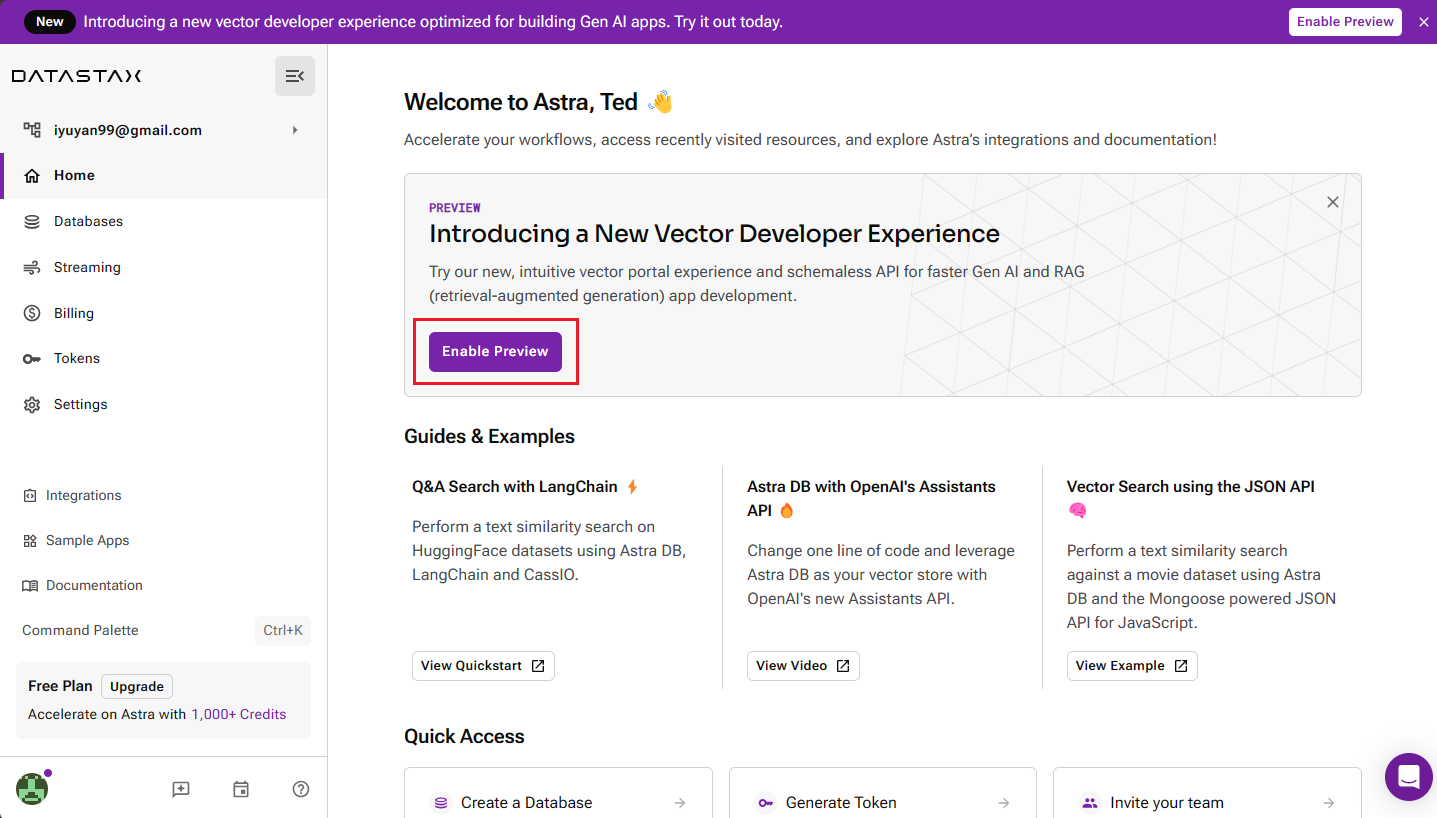
由於我們需要的支援向量資料庫版本目前處於預覽階段,請在控制面板上點擊【Enable Preview】按鈕。
點擊後,您將看到預覽版資料庫的一些特色功能介紹,比如改進的資料監視器(Data Explorer)和更友好的程式連接方法等。請繼續點擊【Enable Preview】進入下一頁。
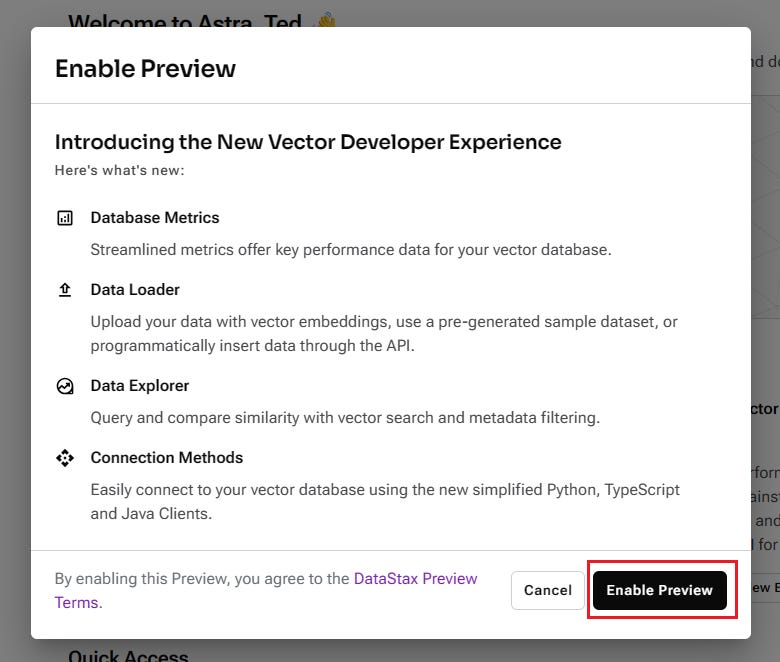
接下來的頁面將展示一些開始之前的重要說明,例如:這個新資料庫是專為生成式 AI 應用設計的,如果不習慣也可以隨時退出預覽等。請點擊【Continue】按鈕以繼續。
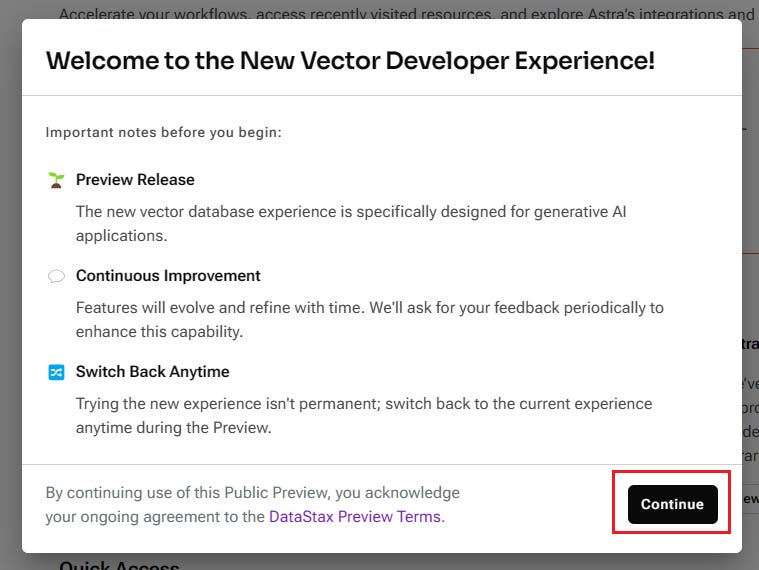
進入預覽版控制面板後,您將看到中間有一個【Create Database】的選項。點擊它以進行下一步。
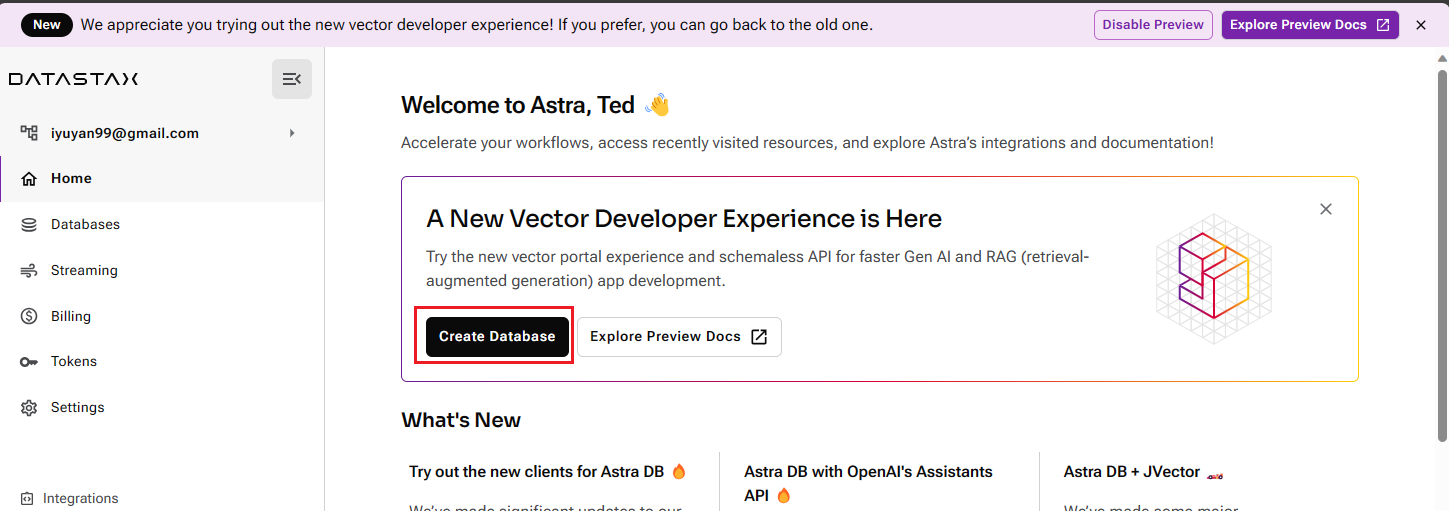
在建立資料庫時,選擇左側的【Serverless(Vector)】作為資料庫類型。
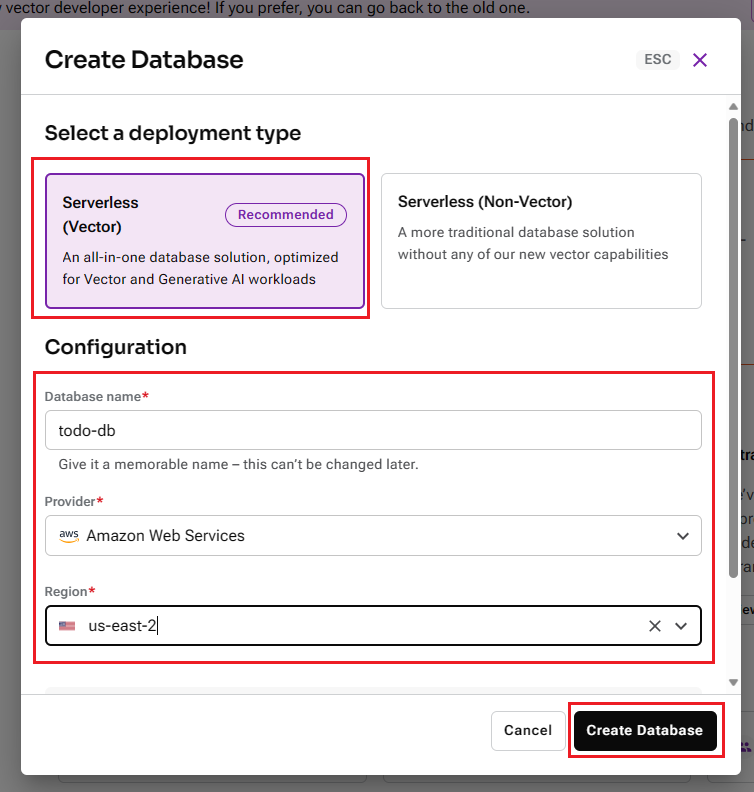
接著是詳細設定部分:
Database name: 在此處輸入您想要的資料庫名稱,例如我這裡輸入的是 "todo-db"。
Provider: 選擇雲端服務的提供商,目前免費選項僅有 Amazon Web Services。
Region: 選擇雲端服務商的機房位置,免費方案目前僅支援 "us-east-2"。
填寫並選擇完畢後,點擊【Create Database】繼續。
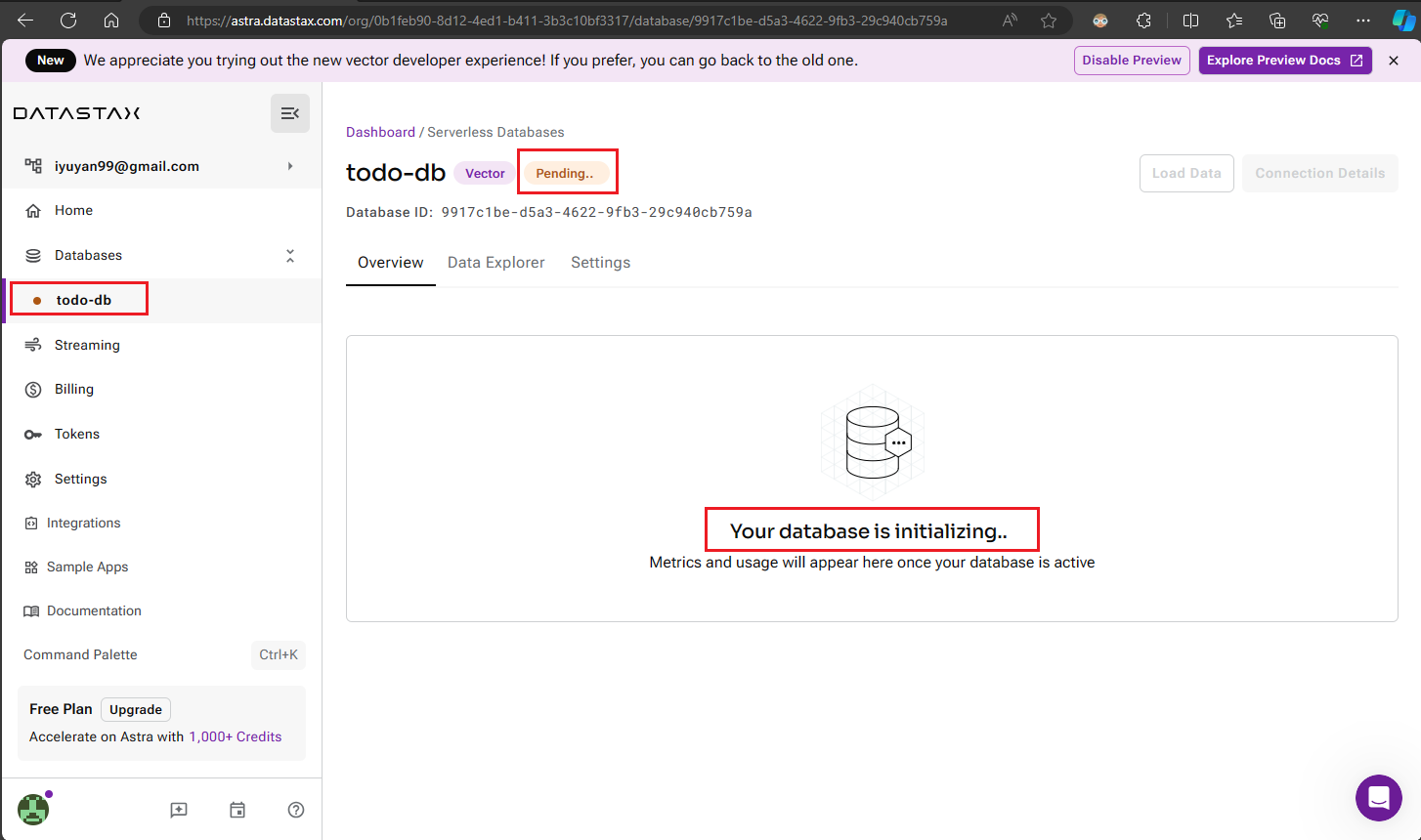
建立資料庫後,您將看到一個顯示 "Pending" 和 "Initializing" 等狀態的頁面,這表示資料庫正在建立中。通常只需等待一到兩分鐘即可完成。
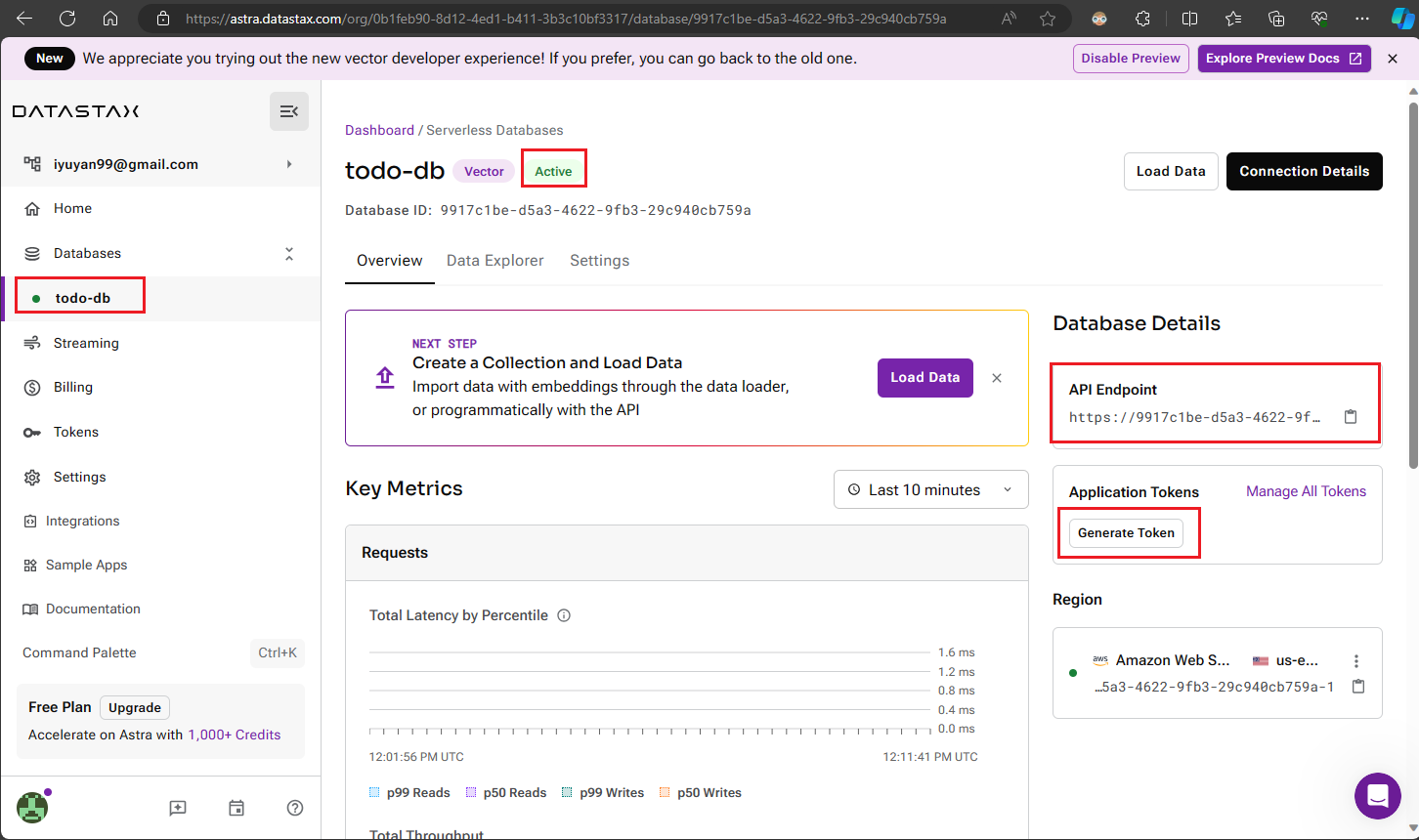
建置完成後,您將看到狀態變為 "Active"。這時,請關注右側的【API Endpoint】欄位,點擊旁邊的複製按鈕,將其儲存下來,稍後設定主機時會用到。然後點擊【Generate Token】以建立我們服務稍後將使用的 Application Token。
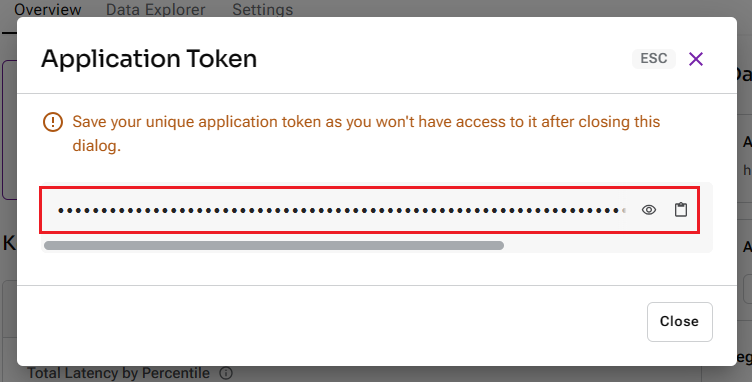
點擊 Create Token 後,您將看到一個新頁面。同樣,請使用複製按鈕將其記下,因為在設定主機環境時也將需要此信息。
部署 Vercel 專案
在完成上述資料庫的建立及關鍵設定之後,請前往我們的 GitHub 教程程式碼首頁,網址為:TaskHelperAPI_Auth_Db_Template。進入網頁後,請滾動到頁面底部並點擊【Deploy】按鈕。
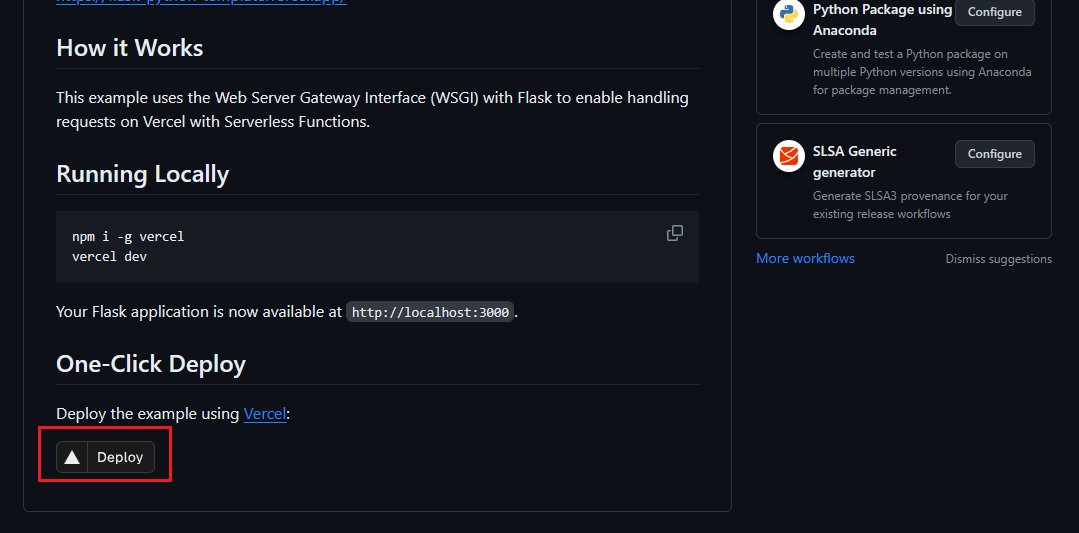
點擊 Deploy 之後,您將會被引導到部署設定頁面。在這裡,請在 Repository Name 欄位填寫您的程式庫名稱,然後點擊【Create】按鈕。
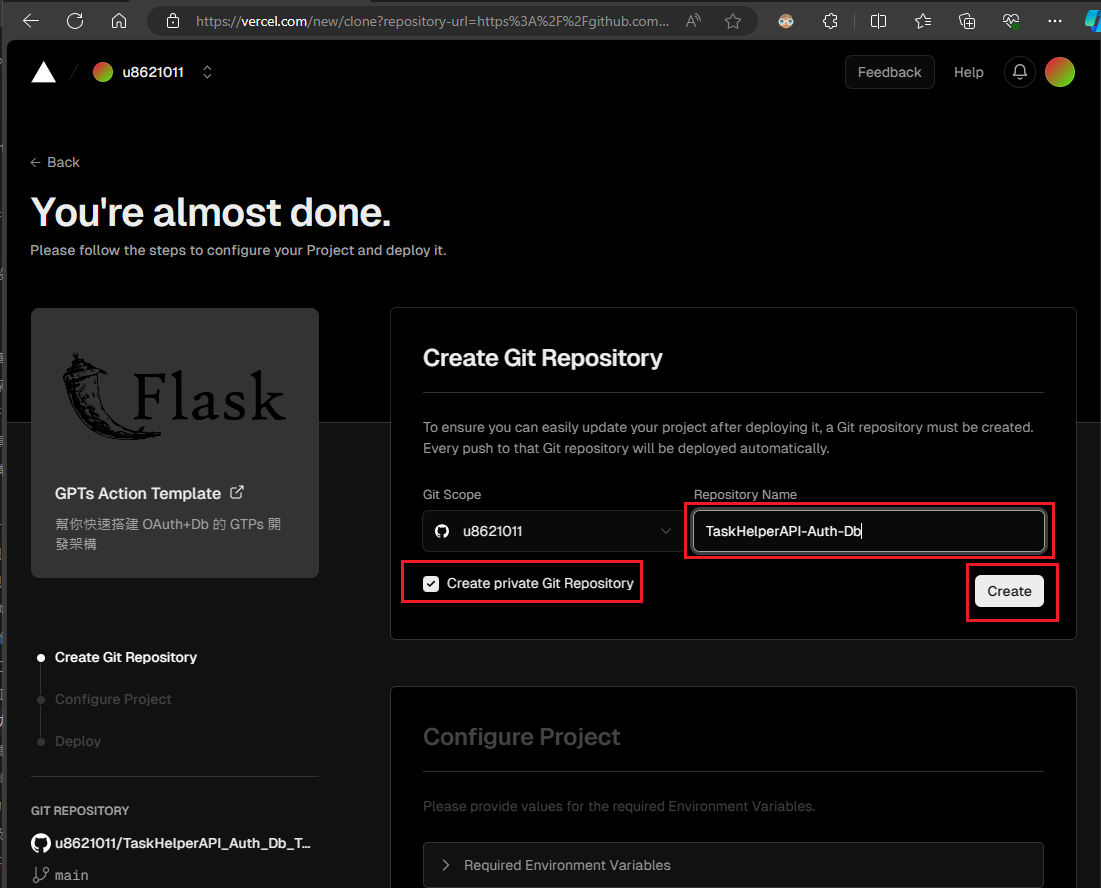
點擊【Create】之後,由於我們的專案需要設定一些環境變量的預設值,您將在相同頁面的下方看到幾個需要填寫的欄位。
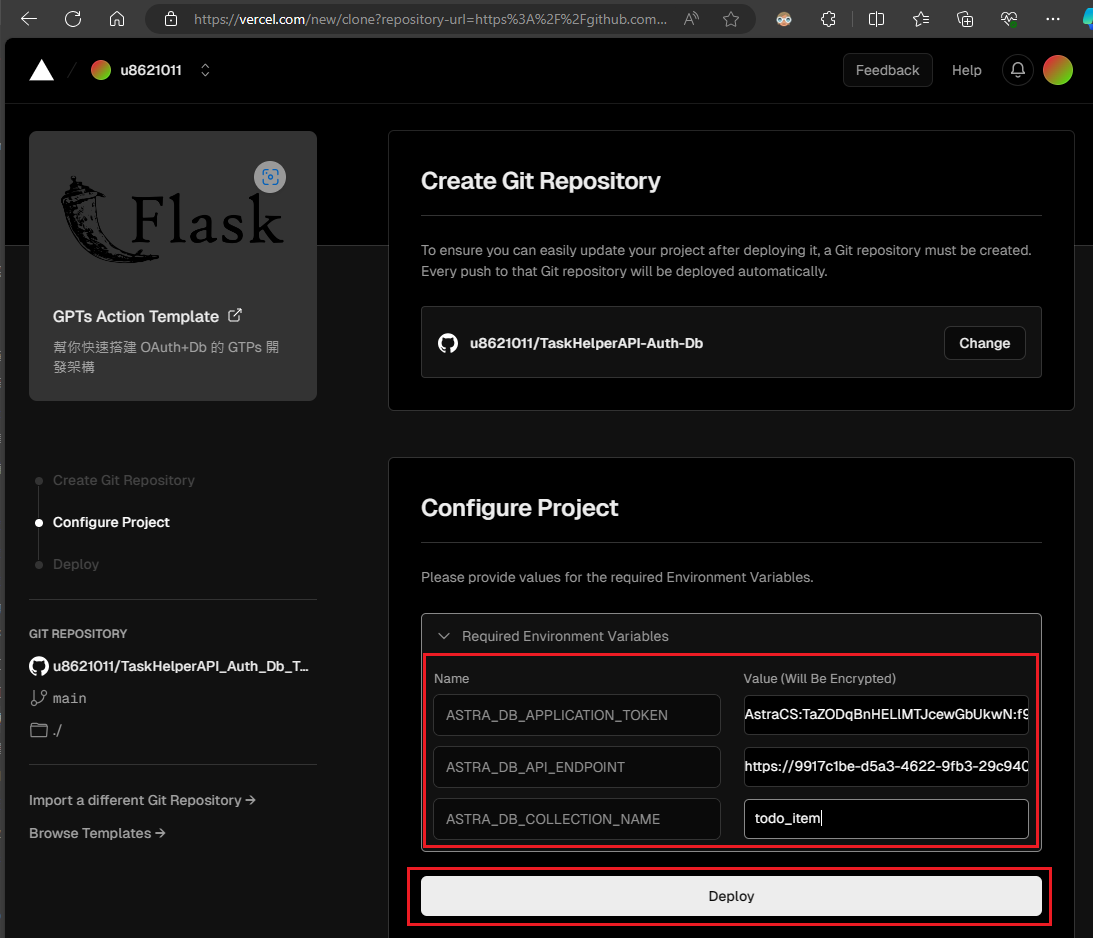
具體需要填寫的內容如下:
ASTRA_DB_APPLICATION_TOKEN: 這是您在建立資料庫時創建的【Application Token】。
ASTRA_DB_API_ENDPOINT: 這是您在建立資料庫時複製下來的【Application Endpoint】。
ASTRA_DB_COLLECTION_NAME: 這是稍後我們待辦事項將存放的 Collection 名稱,概念上,你可以將它視為 Excel 中的一個工作表(sheet)。
(如果需要分隔號,請使用底線,例如 todo_item,否則會有問題。)
填寫完畢後,點擊【Deploy】按鈕進行部署。
部署完成後,系統會導向到一個新頁面如下,請點擊【Continue to Dashboard】。
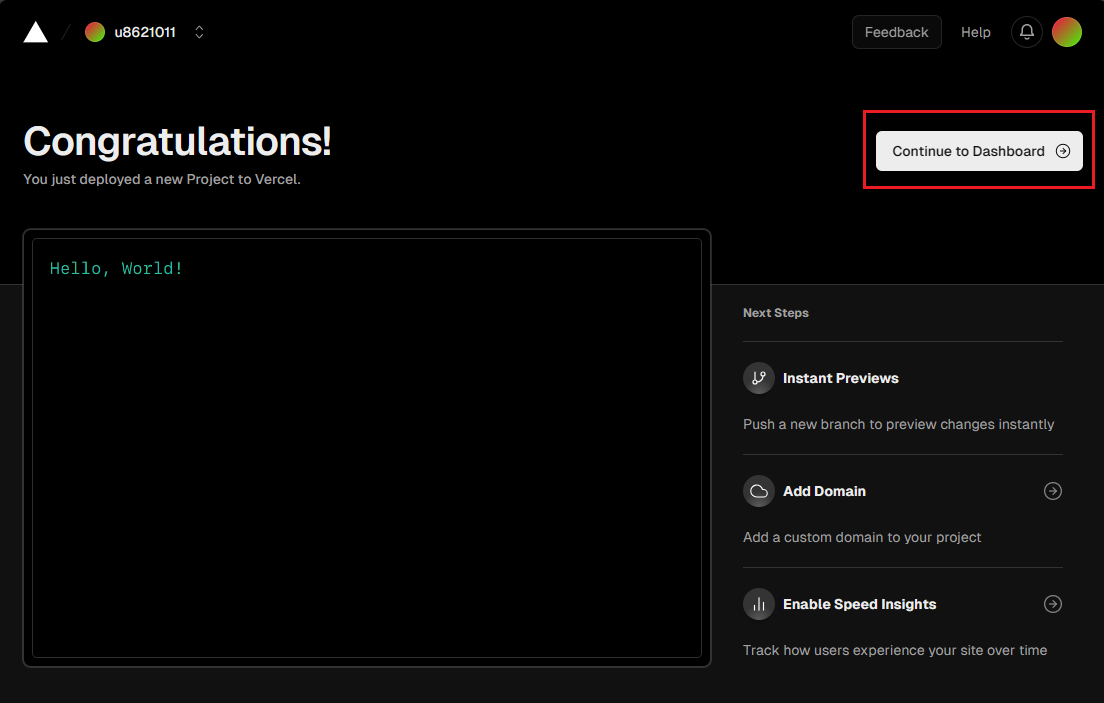
在您新建立的 Vercel 專案首頁中,您將看到 Vercel 分配給您的域名(domains),請將其記下。
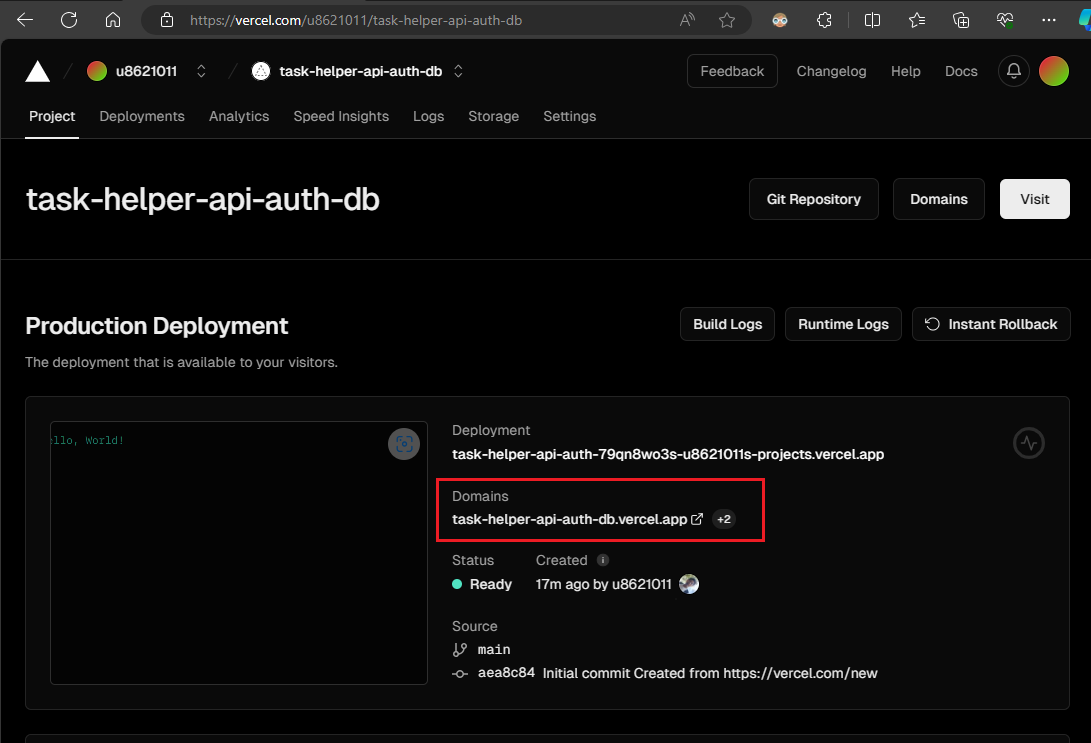
剩下的步驟,包括修改 Vercel 主機的基本設定、設定 PluginLab 插件以及 ChatGPT GPTs Action 等,與我們在上一篇文章《如何在 5 分鐘內為您的 GPTs 加上 OAuth 認證》中的後半部分完全相同。您可以參考該文章,從「修改程式碼以符合個人的 Vercel 主機設定」這一段開始,繼續進行操作。
文章的網址在這裏: 如何 5 分鐘內,幫你的 GPTs 加上 OAuth 認證 - by Ted Chen (substack.com)
資料庫寫入狀況的驗證
在您依照上一篇文章的指南完成了所有 PluginLab、ChatGPT GPTs Action,以及 ChatGPT GPTs 的設定後,您可以立即進行簡單的試用,如下圖與 ChatGPT GPTs 的對話:
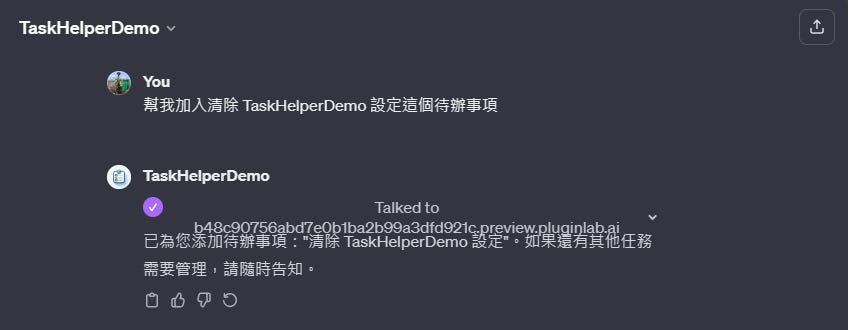
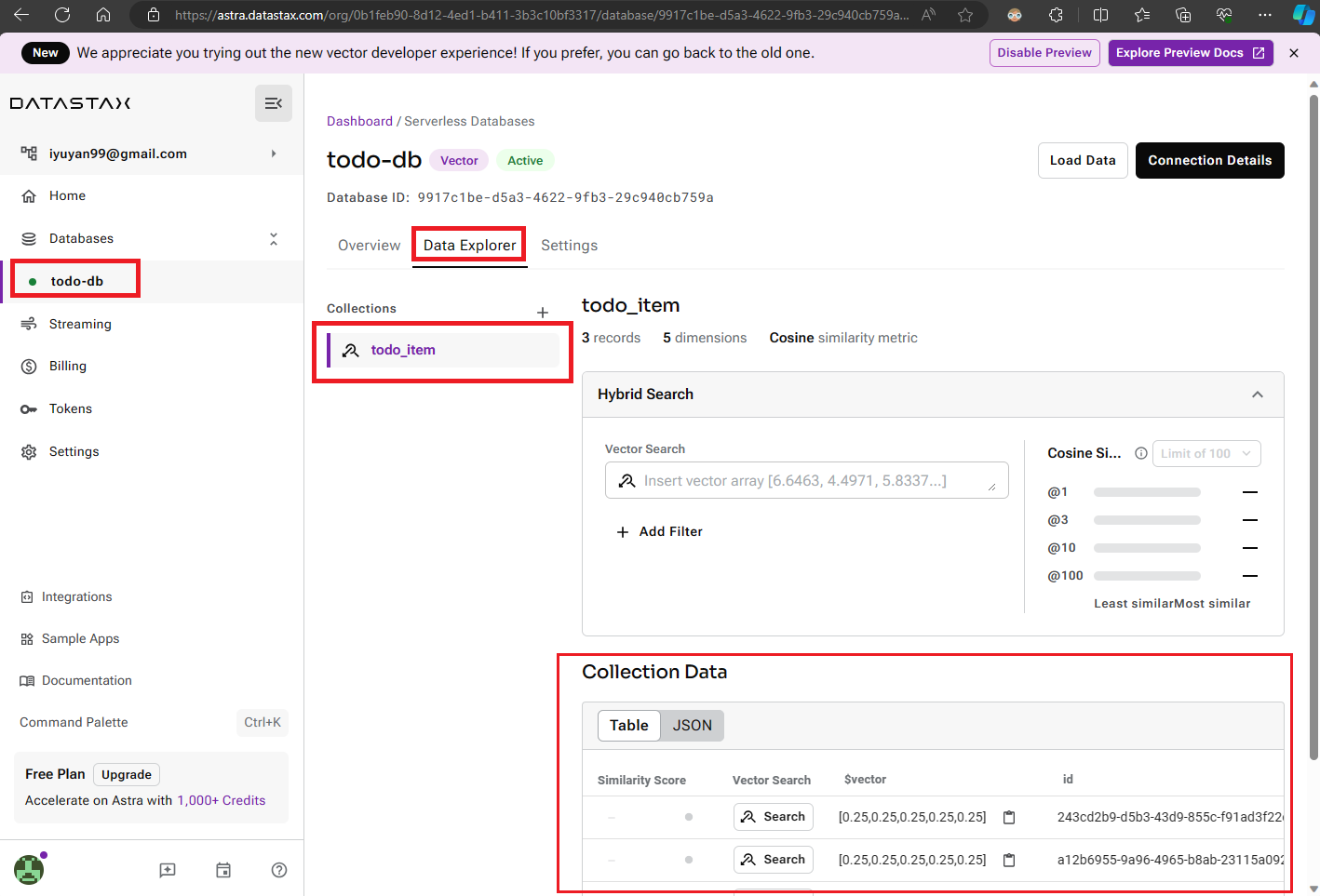
一旦 GPTs 通知您待辦事項新增完成,您可以重新開啟 Astra Db 的控制面板。在這裡,點擊您的 GPTs 使用的資料庫,例如我的是「todo-db」,然後點選【Data Explorer】並選擇您所儲存的 Collection 名稱(例如「todo_item」)。這樣您就能在下方的「Collection Data」區域看到已儲存的資料。
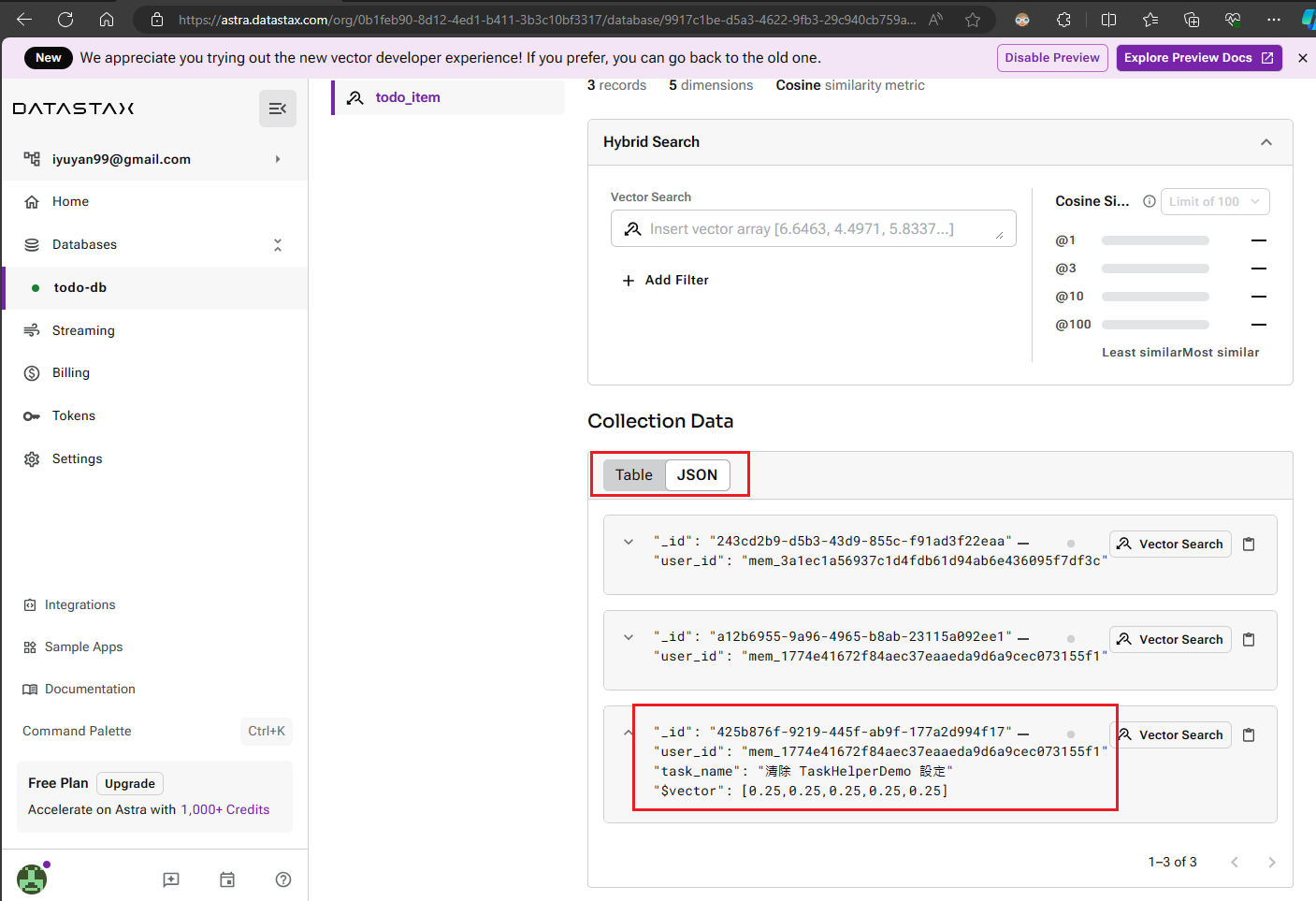
如果您發現在表格式(Table)的界面中無法清楚看到資料,您也可以點擊【JSON】按鈕,然後選擇您想查看的項目。這樣您就能一目了然地看到完整的儲存資料欄位及其內容了
結語
經過連續三週深入淺出地介紹 ChatGPT GPTs 的實作教程,不知道您是否能跟上節奏?我希望這些詳盡的說明能助您一臂之力,打造出您心中理想的 GPTs 第一個基礎架構。如果您錯過了前幾篇文章,別擔心,我在這裡列出了整個教程的所有部分:
加油!