

善用模型記憶的資料合成器:MAGPIE 的創新方法
今天在 Hugging Face 上看到有人分享了一個資料集的合成工具,原本看起來很簡單,但深入了解後,發現內部的合成原理真的非常有趣!他們竟然能用大語言模型(LLM)當初 instruction tuning 的訓練指令,快速生成更多樣的指令,進而展開新的數據用途。這篇文章就來分享我對這項技術的理解與感想
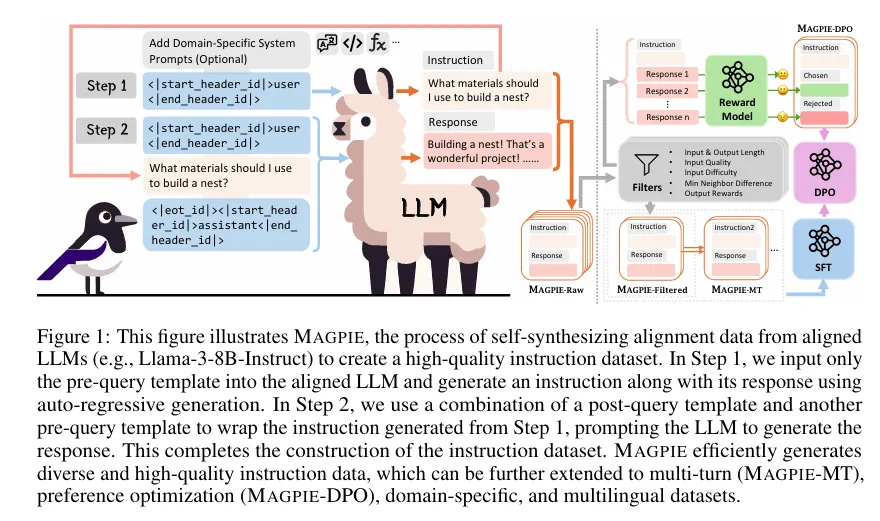
。(from MAGPIE: ALIGNMENT DATA SYNTHESIS FROM SCRATCH BY PROMPTING ALIGNED LLMS WITH NOTHING)
從 LLM 的 Instruction Tuning 說起
首先,我們先理解一個背景知識——什麼是 Instruction Tuning?
簡單來說,這是一個讓大語言模型更「聽話」的訓練過程。在這個階段,研究人員會給模型大量「指令-回應」對的數據,讓它學會如何針對用戶輸入(即指令)生成適合的回應。舉個例子:
指令:如何煮一碗義大利麵?
回應:首先準備義大利麵、橄欖油、大蒜和番茄醬……
這些數據的格式可能是這樣的:
<|start_header_id|>user<|end_header_id|> 如何煮一碗義大利麵?
<|start_header_id|>assistant<|end_header_id|> 首先準備……LLM 通過學習這些數據,內部建立起「如何回應指令」的模型。
善用訓練痕跡:MAGPIE 的核心創新
這一次看到的合成工具 MAGPIE,厲害的地方在於它不需要任何新設計的問題或手工資料標註,而是利用 LLM 在 Instruction Tuning 階段學到的「指令模式」,讓模型自己生成更多的指令!
怎麼做到的?
簡單的模板引導: 他們發現,只要提供這樣一個模板:
<|start_header_id|>user<|end_header_id|>模型就能自動填入一個合理的指令,像是:
如何建造一個鳥巢?原因是模型在訓練時,已經學習到「看到這個模板後,應該補上用戶的一個指令」。
重複利用自回歸生成: 模型不僅可以生成指令,還可以用生成的指令作為新輸入,讓模型再生成對應的回應。例如:
指令:如何建造一個鳥巢?
回應:你可以使用乾草和羽毛來建造……
自動化與擴展:
不僅僅是單一指令,還能生成多回合對話。
透過特定的提示設計,可以生成針對數學、編程等領域的專用指令。
支援多語言數據,如中文、德文或西班牙文的指令生成。
為什麼這麼重要?
傳統生成模型訓練數據的方法,往往需要:
種子問題:需要設計一些基本的啟動問題,讓模型生成後續內容。
人工標註:必須由人類進行校正,確認數據質量。
但 MAGPIE 的方法完全避免了這些麻煩:
零種子問題:利用模型內部的記憶分佈,自動生成指令。
高效且低成本:不需要人工參與,數據生成速度快且品質高。
大規模生成:可在短時間內生成數百萬條指令與回應對,用於進一步訓練模型。
我的心得與啟發
這樣的設計讓我印象深刻的是,它充分展現了「重複利用模型記憶」的巧妙性。一個訓練過的模型,不僅僅是用來執行任務,還能用來挖掘更多的數據。這讓我思考,是否未來的 AI 訓練中,我們可以更多地關注如何善用模型已學到的東西,而不是一味依賴外部的人工數據。
同時,MAGPIE 的邏輯也很適合應用在其他場景,比如多語言翻譯、專業領域訓練甚至是即時對話生成。
總結
MAGPIE 展示了一個讓人耳目一新的數據生成方式,它以簡單的模板撬動了 LLM 的內部記憶分佈,用極低的成本創造出高質量的指令數據,對於 LLM 的持續優化有著深遠的意義。如果你也對模型內部的運作機制感興趣,或正在尋求高效生成數據的工具,不妨親自了解一下這項技術!
你對這樣的方法是否也感到興趣呢?歡迎交流!