


HtmlRAG: HTML is Better ThanPlain Text for Modeling Retrieved Knowledge in RAG Systems, ChatGPT 導讀

完整 ChatGPT 導讀:
HtmlRAG: HTML is Better ThanPlain Text for Modeling Retrieved Knowledge in RAG Systems, ChatGPT 導讀

(資料來源: HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems)
ChatGPT 導讀
文章標題翻譯
HtmlRAG: HTML 比純文字更適合於 RAG 系統中建模檢索知識
重點摘要
本文探討在檢索增強生成系統(RAG)中使用 HTML 作為檢索知識的格式是否能比純文字更好地保留結構和語義信息。傳統的 RAG 系統通常將 HTML 轉換為純文字,但這樣會丟失 HTML 的結構化和語義資訊。本文提出了一種新方法——HtmlRAG,直接使用 HTML 格式,並設計了高效的 HTML 清理和修剪策略以解決冗長和噪聲問題。
核心技術包括:
HTML 清理與壓縮:去除無用的 CSS、JavaScript 和其他冗餘信息,同時保留結構信息。
基於樹結構的修剪方法:使用兩階段的 HTML 修剪策略,基於文本嵌入和生成模型對 HTML 進行剪裁以縮短長度。
實驗與驗證:在六個問答數據集上進行實驗,結果顯示 HTML 格式相比純文字格式在保留語義信息上更優。
主要觀點
HTML 是更適合於建模檢索知識的數據格式,因其能保留豐富的結構和語義信息。
長文本建模能力的提升使得處理 HTML 成為可能,但需解決過多標記導致的冗長問題。
提出的 HtmlRAG 系統在性能上超越了基於純文字的傳統方法。
關鍵概念
檢索增強生成 (Retrieval-Augmented Generation, RAG):結合外部知識和生成模型以提高回答準確性的方法。
HTML 清理 (HTML Cleaning):一種去除無用元素(如 CSS 和 JavaScript)的過程,用於縮短 HTML 文件長度。
HTML 修剪 (HTML Pruning):基於嵌入模型和生成模型對 HTML 樹結構進行剪裁以保留關鍵內容的過程。
結構化信息 (Structured Information):HTML 提供的層級標題、表格等信息,有助於保留語義完整性。
語義嵌入 (Text Embedding):將文本轉換為數值表示以計算語義相關性。
延伸概念
語言模型 (LLM):如 GPT 等大規模預訓練模型,用於生成自然語言。
長上下文窗口 (Long Context Window):LLM 的能力之一,能處理更長的輸入文本。
樹結構建模 (Tree-Based Modeling):基於 HTML 的 DOM 結構建立抽象層次,用於修剪和處理。
生成模型修剪 (Generative Pruning):利用生成模型從整體上評估並裁剪 HTML 區塊的技術。
演算法說明
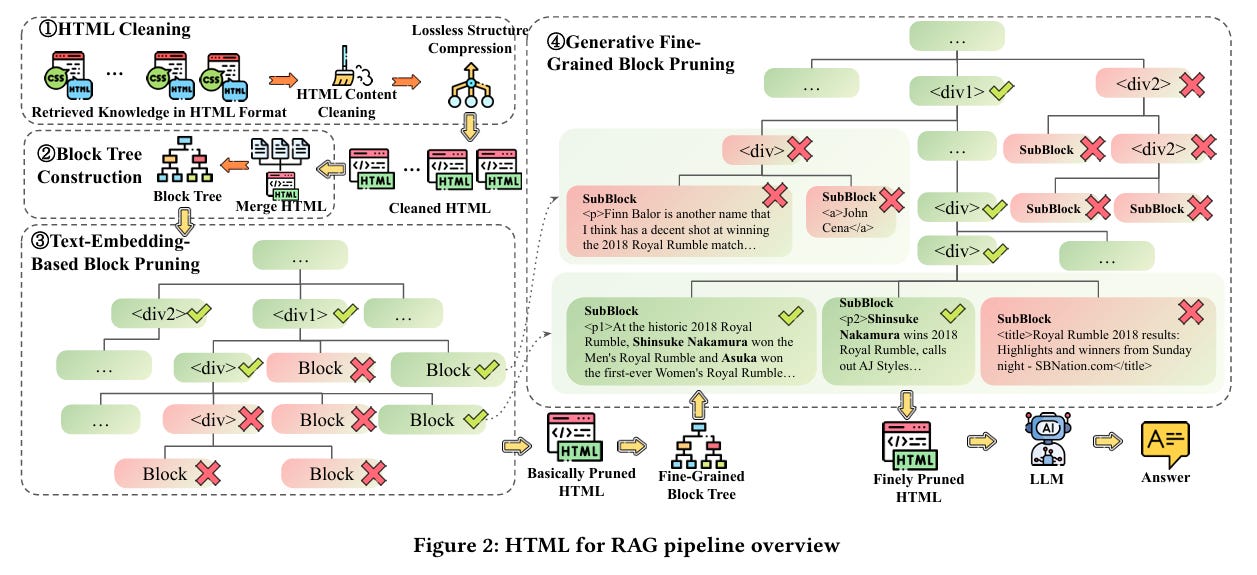
HtmlRAG 的關鍵技術是兩階段的修剪方法:
嵌入模型修剪:
根據用戶查詢和文本嵌入的相似度計算 HTML 區塊的相關性。
刪除低相關性的區塊,重新調整 HTML 結構。
生成模型修剪:
使用生成模型基於整體結構進行更細緻的區塊評估和裁剪。
生成每個區塊的標籤路徑並基於生成概率計算區塊分數。
(資料來源: HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems)
生活化例子
假設我們從網頁中檢索了一個包含多個表格的 HTML 文檔,傳統方法會轉換為純文字,導致表格信息變得難以理解。而使用 HtmlRAG,系統保留了表格的結構,並通過修剪去除無用的部分,最終讓模型理解到有意義的數據(例如,某表格中的統計數據或排名資訊)。
若需更深入的解釋,您可以參考這裏:
HtmlRAG: HTML is Better ThanPlain Text for Modeling Retrieved Knowledge in RAG Systems, ChatGPT 導讀