

以下可是用 LLM 系統性撰寫出來的成果,大家覺得怎麼樣呢?
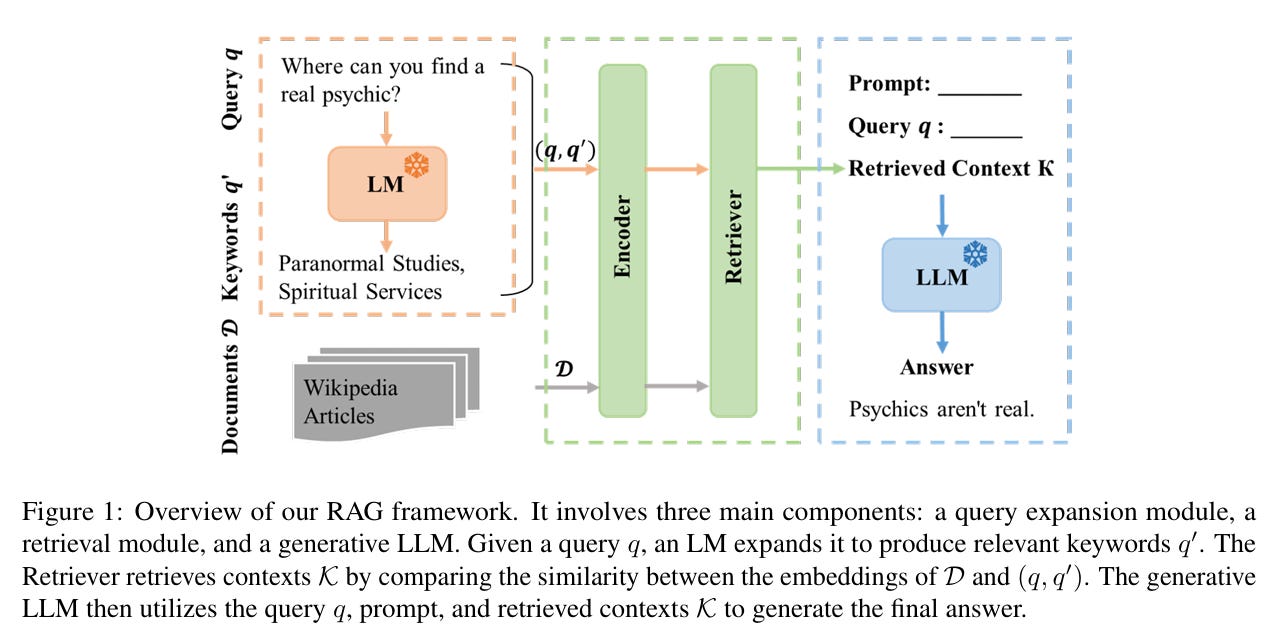
有沒有想過,如果考試時能一邊翻書、一邊作答,會是什麼情況?在 AI 的世界裡,最近就出現了類似「邊生成、邊檢索」的技術,幫助大型語言模型在回答問題時即時查資料,讓答案又快又準。前陣子看了一篇研究,提到兩個新概念——「對比上下文學習」和「檢索步幅」,讓我覺得特別有意思。它們都是 RAG(Retrieval-Augmented Generation, 檢索增強生成)技術的新嘗試,聽起來就像替 AI 裝了更多「智慧小幫手」,讓它不只憑既有記憶回答,也能靈活查詢最新知識。
先說說背景:我們都知道,像 ChatGPT 或 BERT 這類大型語言模型再厲害,也免不了有「亂掰」或「硬拗」的時候。畢竟它們內建的知識庫都是訓練時期的資料,沒有天天更新。所以研究人員就想:「如果邊回答邊到外部知識庫(像維基百科)查資料,不就能及時補充模型缺少的資訊嗎?」於是就有了 RAG 的概念。早期的 RAG 圍繞「怎麼給提示、怎麼切分文件、要不要邊寫邊查」等細節不停優化,才發展出我們今天要聊的兩個重點:對比上下文學習和檢索步幅。
「對比上下文學習」(Contrastive In-Context Learning)聽起來很抽象,但實際上蠻直觀:在教 AI 如何回答時,除了給它看正確範例,也額外展示一個錯誤示範,讓它在「正、反對照」之間去理解什麼才是「對」。這有點像我們學外語時,常常會看到「正確句型」和「常見錯誤」並排,比較之下就能抓到關鍵差異。論文中的實驗指出,這種做法對一些模糊或容易誤判的問題特別有效,能提高 AI 的回答準確度。換句話說,AI 也和人類一樣,需要「這樣行、那樣不行」的對比式學習才能更快掌握重點。
另一個概念叫「檢索步幅」(Retrieval Stride)。想像我們在寫文章時,每隔一小段就暫停一下,到網路上找更多資料,然後再繼續寫。RAG 模型也是一樣,它會在生成回應的過程中,隔一段就重新檢索外部知識。好處是可以動態補充最新資訊,避免一次查完後就再也沒有後續更新的狀況。不過也像我們寫作時,如果查資料太頻繁,思路容易被打斷;但查太少又怕漏掉關鍵訊息,所以設定多少「步幅」其實蠻重要的。就跟「Open Book 考試」雖然能一邊寫一邊翻書,但翻得太勤也不見得好,最後可能會花更多時間彙整。研究中顯示,如何拿捏檢索步幅,確實會影響模型的回答品質與連貫度。
這兩個概念實際應用在哪裡呢?比方說,面對那些定義曖昧的問題,像「如何判定食物健康?」如果只給 AI 一堆正確示例,它可能知道基本原則,但加入一些常見錯誤示範,會讓它更精準地分辨哪些觀念是迷思、哪些才對。至於「邊生成邊查」的檢索步幅,適合用在想確保資訊最新又不想被過度干擾的情況,比如撰寫關於全球暖化的報告:你也許希望每寫一段都查一次最新數據,而不是一口氣查好多資料再放著不管,卻也不至於每一句都要被打斷去做搜尋。
綜合來看,對比上下文學習能大幅提升 AI 對「正確 vs. 錯誤」訊息的分辨力,而檢索步幅則讓 RAG 的「邊查邊寫」更具彈性。雖然它們也各有侷限,如對比示範需要足夠的反例素材,檢索步幅還要考慮檢索效率與整體思路,但從研究結果看來,的確是值得關注的新思路。如果未來能自動判斷什麼時候該「翻書」、什麼時候該「寫文」,就能既保留上下文連貫,又確保時時更新關鍵資訊,想必會讓語言模型更上一層樓。想像一下,以後的 AI 不但擁有龐大的「既有知識」,還能透過一個小書僮隨時補充、校正與鞏固,整體專業度應該可以再度提升。
若你也覺得這兩個概念有趣,可以想想:對比上下文學習除了對付模糊或專業題目,還能不能應用在其他「容易出錯」的領域?又或者,邊寫邊查這件事在你的日常生活中是怎麼運作的?是每打一段就要去搜尋一次資料,還是乾脆一次查到底、寫作時就專心流暢?這些思考都能幫助我們更靈活地運用相關技術。總之,這篇研究用「對比」和「步幅」這兩把鑰匙,替 RAG 打開了許多新的想像空間。我也很期待未來有更多人把它們帶到不同的應用場景,看看能碰撞出什麼有趣的火花。祝閱讀愉快!