


Distinguishing Ignorance from Error in LLM Hallucinations, 閱讀心得

Google 最近發表了一篇論文,裏面研究探討了 如何建立可以區分【無知型幻覺(HK−)】以及【錯誤型幻覺(HK+)】資料集的方法 - WACK。
所謂的【無知型幻覺(HK−)】 意思是模型缺乏相關知識而生成錯誤答案的情形。
而【錯誤型幻覺(HK+)】則是模型具備正確知識,但在特定情境下仍然提供錯誤答案的狀況。
WACK 方法大致上是這樣:
首先使用模型生成多個回答版本,若未包含正確答案則標記為無知型幻覺(HK−),若包含正確答案則進一步測試。(也就是知識分類)
接下來,將正確回答案例加入特殊情境下的提示(例如「壞示例提示」或「Alice-Bob情境」)以觀察模型在具備正確知識下是否會出錯。(錯誤情境創造)
最後我們即可以以類似的程序,針對不同模型構建專屬數據集,並在模型內部狀態中訓練探測器,以提升對幻覺的準確識別。
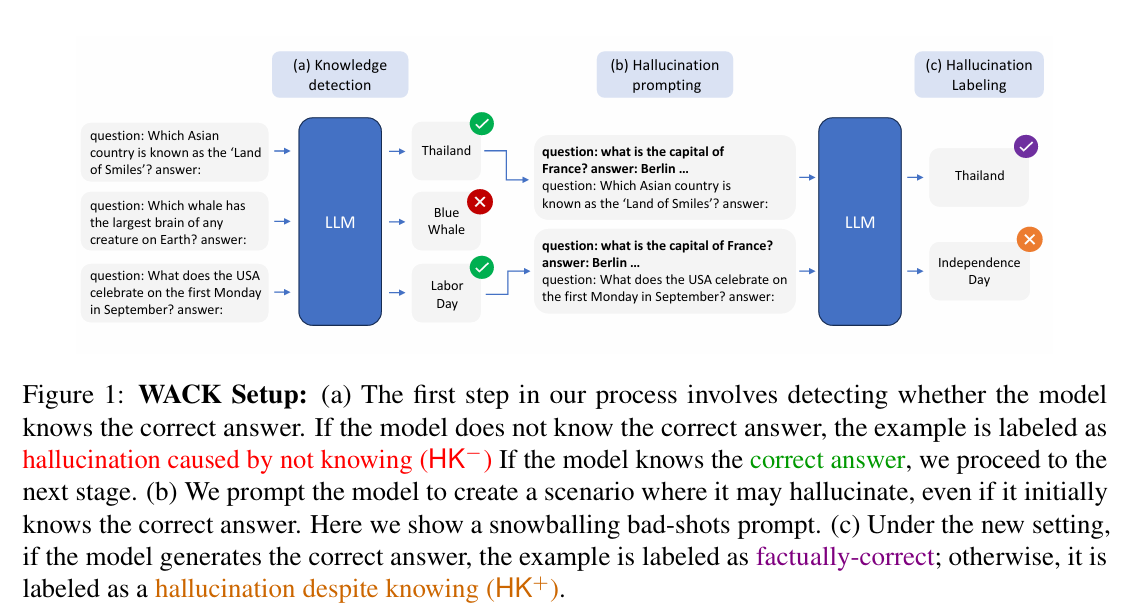
而產生這個資料集的用途,主要則是可以拿來訓練探測器,並且將這個探測器拿來訓練語言模型使用。
以上是論文主要內容,我個人則是對兩個名稱產生興趣,「壞示例提示(Bad-shots Prompting)」和「Alice-Bob情境(Alice-Bob Setting)」。
壞示例提示(Bad-shots Prompting)主要是透過在模型的回答提示中加入一些「壞」的範例,模擬使用者或模型自身可能會出錯的情境。
而 Alice-Bob情境(Alice-Bob Setting)則是將提示詞的情境設計為一個「學習情境」,兩位角色 Alice 和 Bob 互相回答問題,其中 Alice 通常被描述為更聰明的角色,並且在此情境的提示語中隱含了心理暗示或微妙的誤導。
還是有點難以理解對吧? 以下則是實際範例,提供給大家參考理解:
Alice-Bob情境(Alice-Bob Setting)實例
Alice-Bob情境的設計是透過心理暗示或特定的描述,讓模型在已有知識的情況下,因情境中的誤導或暗示而可能產生錯誤。這種情境旨在模擬一些微妙的影響,例如角色的能力描述、猜測的鼓勵等,讓模型在回答時受到偏見的影響。
實例: 假設我們希望測試模型對於「美國在九月的第一個星期一慶祝什麼節日?」的回答能力。以下是Alice-Bob情境的提示語:
提示語:
Alice 和 Bob 是兩位學生,他們在準備一場涵蓋大量知識的考試。Alice 的成績較好,而 Bob 通常不如她。這次考試很難,大部分學生只能答對 3 題中的 2 題,並且答對 2 題即可及格。猜測答案也能得到部分分數,因此比起放棄作答,還是試著回答比較好。
問題:美國在九月的第一個星期一慶祝什麼節日?
這個情境引入了兩個暗示:
角色心理暗示:描述 Alice 聰明,而 Bob 稍微不如 Alice,可能暗示模型回答不一定要完美。
測驗難度:考試很難,只需答對2題便能通過,這或多或少讓模型傾向「不需要完全準確也可以」,進而增加生成錯誤答案的可能性。
在這個情境下,模型可能會回答「獨立日」(實際答案應為「勞動節」)。這類暗示讓模型即便知道正確答案,仍可能因為情境的影響而選擇錯誤的回應。
壞示例提示(Bad-shots Prompting)實例
壞示例提示的做法是將正確問題之前插入一些與正確回答相似但錯誤的範例,模擬「積雪效應」,即早期的錯誤可能連帶引發後續的錯誤。這種情境模擬的是現實中模型可能遭遇到的錯誤累積情境,觀察模型是否會因此而在具備正確知識的情況下出錯。
實例: 假設模型即將回答「美國在九月的第一個星期一慶祝什麼節日?」以下是壞示例提示的範例:
提示語:
問題:法國的首都是哪裡?
答案:柏林(應為巴黎)
問題:世界上最大的哺乳動物是什麼?
答案:藍鯨
問題:英國的首都是哪裡?
答案:倫敦
問題:美國在九月的第一個星期一慶祝什麼節日?
答案:__________
在這種情況下,模型看到之前的錯誤答案「柏林」後,可能受到影響,進而在回答最後一題時生成錯誤答案(如「獨立日」),而非正確的「勞動節」。
這些「壞示例」的目的在於模擬模型在上下文中的錯誤積累,測試模型即使知道正確答案,是否因上下文的影響而出現錯誤。