
ChatGPT 跨界應用週報(第二期)
從 OpenAI 學習到 ChatGPT 實務應用

本週精彩圖表
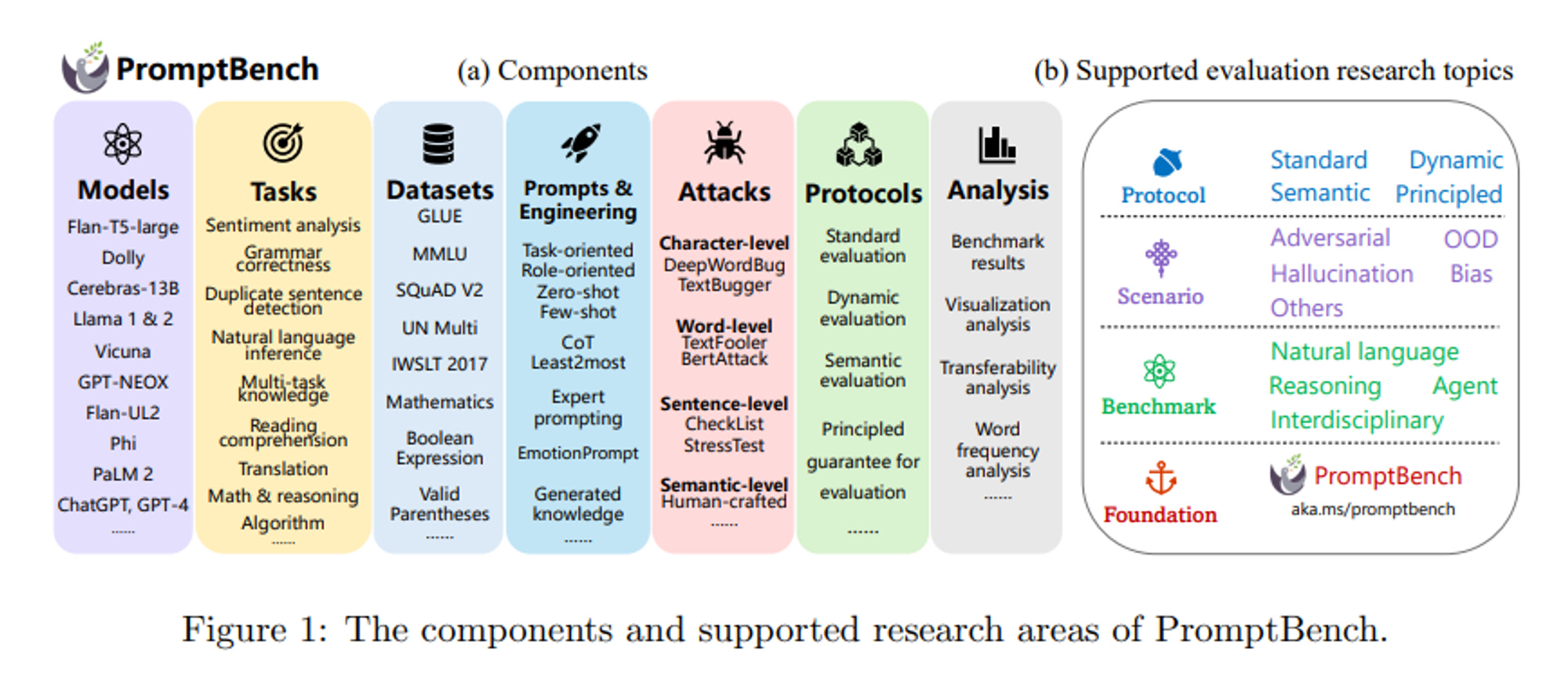
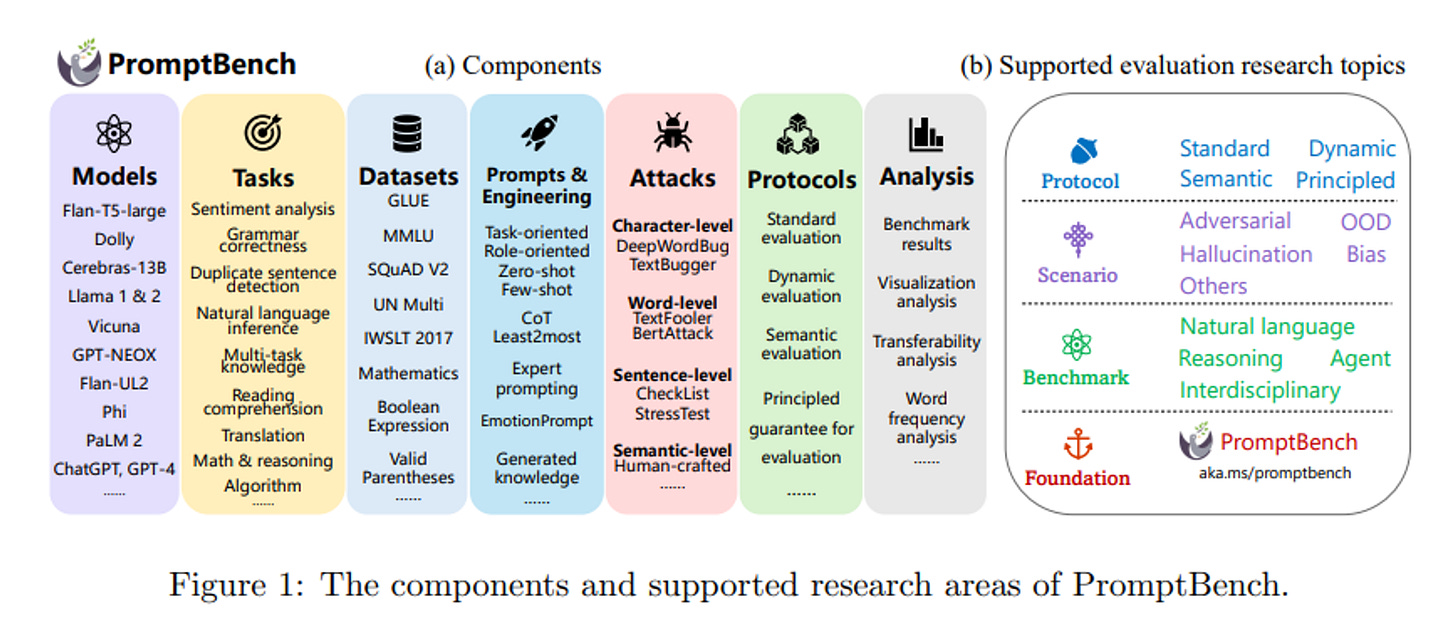
(所有大型語言模型研究領域中 PromptBench 支援的元件內容,來源: PromptBench: A Unified Library for Evaluation of Large Language Models)
前言
本期週報沿用上一期的結構及部分內容,繼續為大家帶來 “OpenIA 官方提示工程指南 - 註釋” 的精彩內容。
另外,最近在網路上發現了一個熱心朋友分享的案例,他在營造業中巧妙應用 GPTs 進行工安提醒和分析。這個案例不僅深度運用了GPTs,原作者還慷慨分享了他實施這一應用的過程,希望透過這個案例的分享,可以讓相同對 GPTs 應用探討有興趣的朋友們,有進一步的啓發。
最後,對於那些專注於大型語言模型的訓練、選型及評估的讀者來說,本期我們還將介紹一個由微軟開源的全面 LLM 工具庫,同時我們也找到了一個介紹頗詳細的中文 Youtube 影片,如果想對這個工具庫全面理解的朋友,很建議您可以找個時間觀看。
本週內容
OpenAI 官方提示工程指南 - 註釋
策略一、撰寫清晰的指令
提示技巧 1-4:明確指出完成任務所需的步驟
提示技巧 1-5:提供範例
提示技巧 1-6:指定期望的輸出長度
ChatGPT / GPTs 應用分享
運用ChatGPT強化現場危害辨識能力
精彩文章(論文)分享
微軟開源了一個完整的 LLM 評估框架 PromptBench: A Unified Library for Evaluation of Large Language Models
OpenAI 官方提示工程指南 - 註釋
(此段落為 OpenAI 官方提示工程指南的註釋,原文請參考: Prompt engineering - OpenAI API)
策略一
撰寫清晰的指令
這些模型無法讀懂你的想法。如果輸出內容太長,就請求簡短回答。如果輸出過於簡單,請求專業級的寫作。如果你不喜歡現有的格式,展示你想要的格式。模型越不用猜測你的需求,你得到想要的答案的機率就越大。
提示技巧 1-4:明確指出完成任務所需的步驟
有些任務最好透過一連串的步驟來明確指定。將這些步驟清楚地寫出來,可以讓模型更容易地遵循。
提示範例:System: 依照以下逐步指示來回應 User 的輸入。 步驟 1 - 用戶將提供一段用三重引號包圍的英文文本。請將這段文本總結為一個句子,並以「總結:」作為前綴。 步驟 2 - 將步驟 1 中的總結翻譯成台灣的國語(繁體中文),並以「翻譯:」作為前綴。 User: """在這裡插入英文文本"""
提示技巧 1-5:提供範例
提供適用於所有範例的一般性指示通常比透過提供特例的提示方式更有效率,但在某些情況下,提供範例可能更為簡單。例如,如果你希望模型複製一種特定的回答使用者查詢的風格,而這種風格難以明確描述,這時就可以使用「少量示例」提示。
提示範例:System: 以如下方一致的風格回答。 user: 教我學習英文的耐心。 Assistant: 學習語言如同種植一棵樹;最初只是一顆小小的種子,但隨著時間和耐心,它將成長為茂盛的大樹。每天的堅持,就像滴水穿石,最終會達到流利。 User: 教我如何克服學習英文的障礙。
提示技巧 1-6:指定期望的輸出長度
你可以要求模型產生特定目標長度的輸出。目標輸出長度可以用字數、句數、段落數、項目符號等來指定。但請注意,指示模型生成特定數量的字數並不會非常精確。模型更可靠地生成具有特定數量段落或項目符號的輸出。
提示範例一:用戶: 請用大約50個字來總結由三重引號包圍的文本。 """在這裡插入文本"""提示範例二:
User: 請用2個段落來總結由三重引號包圍的文本。 """在這裡插入文本"""提示範例三:
User: 請用3個項目符號來總結由三重引號包圍的文本。 """在這裡插入文本"""
GPTs 應用案例
運用ChatGPT強化現場危害辨識能力
還記得在 《GPT-4V 微軟評測報告 》第九章實測 時,有一個章節提到工安方面的應用(文章網址: GPT-4V 的創新應用 - 產業上的可能應用)。
但是在看到這篇臉書上的分享後,對於 GPTs 在工安上的可能應用上,更令人驚艷並且印象深刻。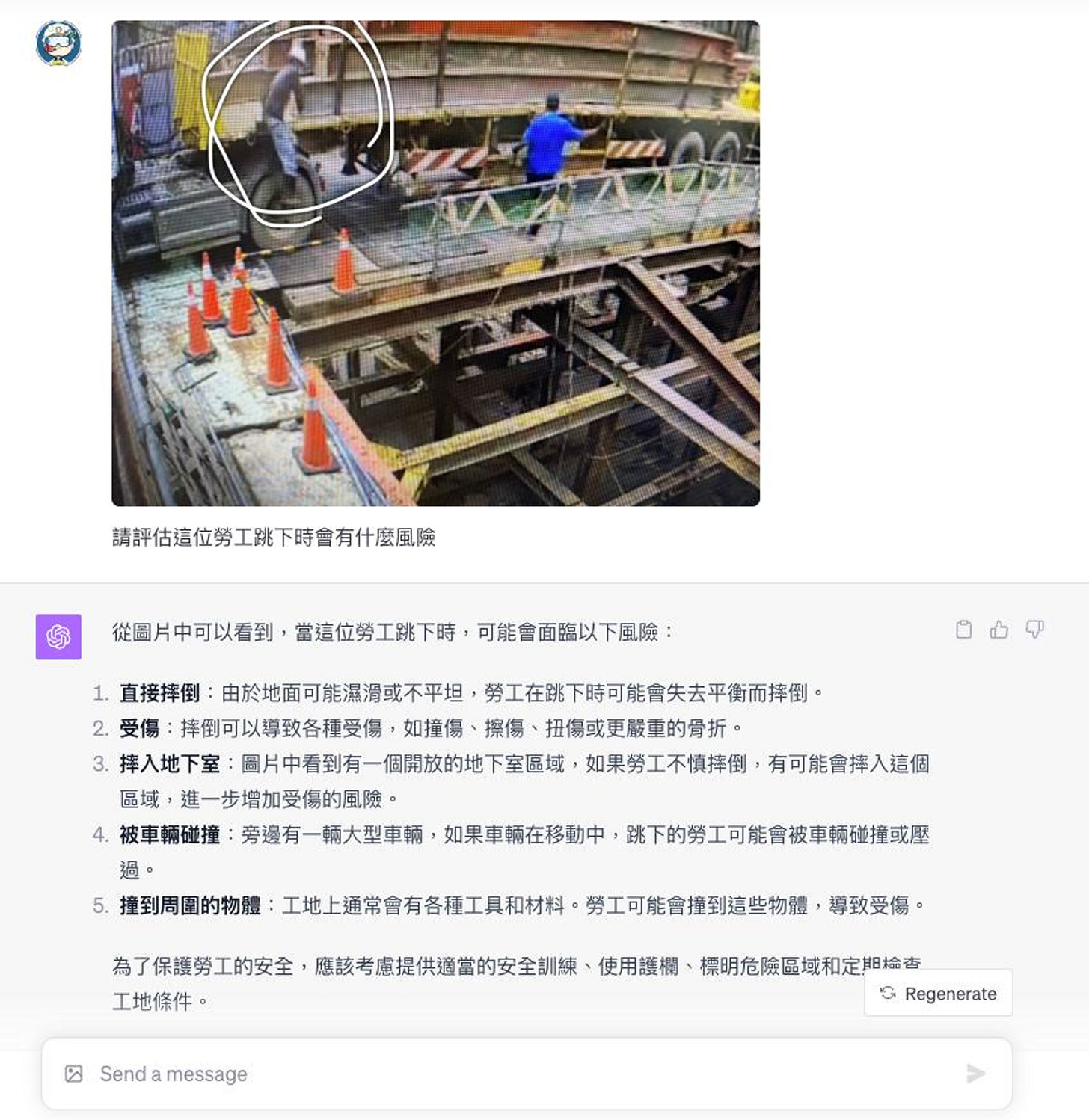


原始的文章連接大家可以參考這裏(很感謝 Alan Lee 大大的同意分享): https://www.facebook.com/groups/753980442028763/permalink/1545615009531965/
另外 Alan Lee 大大也在自己的臉書上,很慷慨的公開了他的實做細節,原始連接大家可以參考這裏: https://www.facebook.com/groups/753980442028763/permalink/1549020269191439/
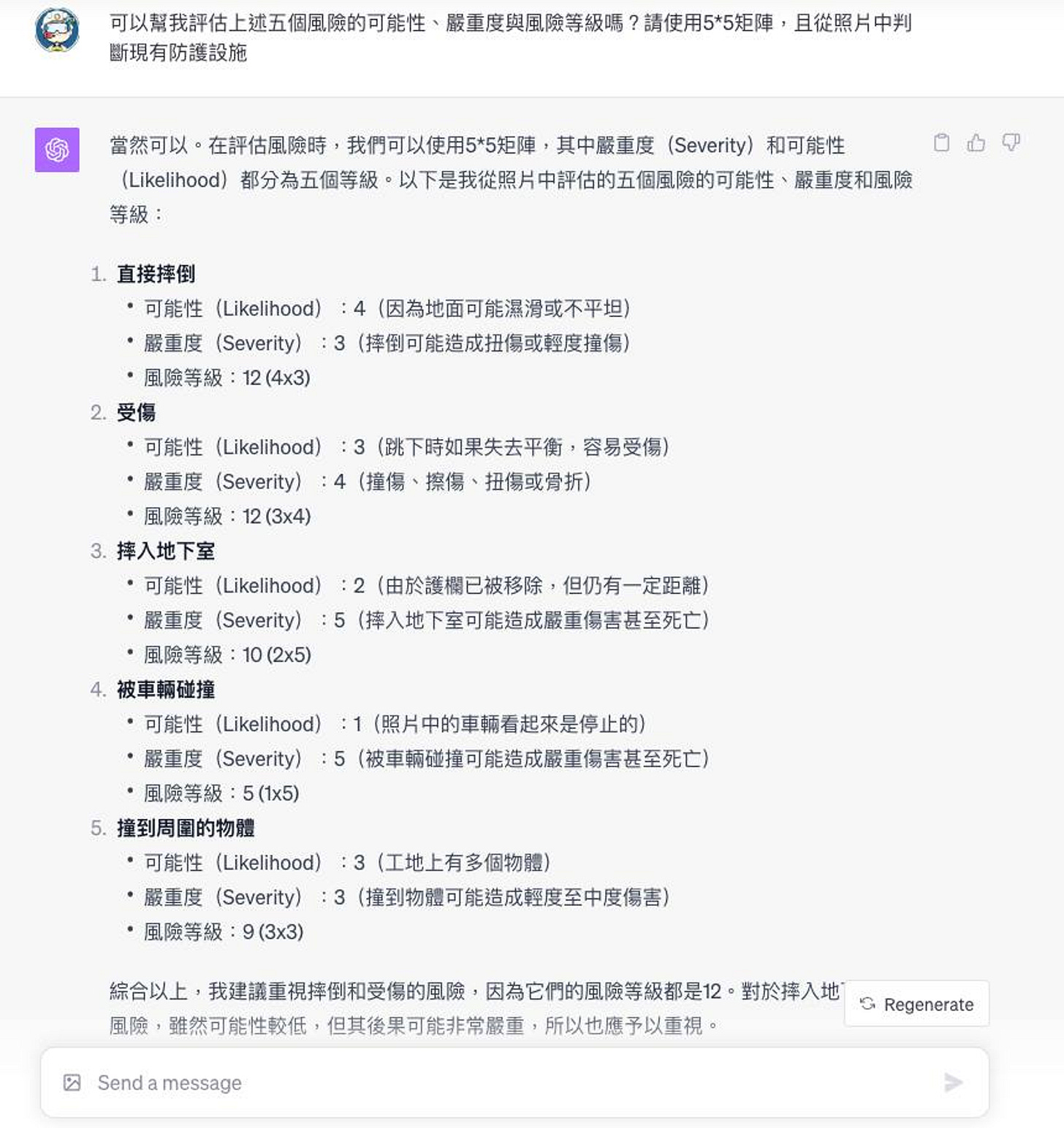
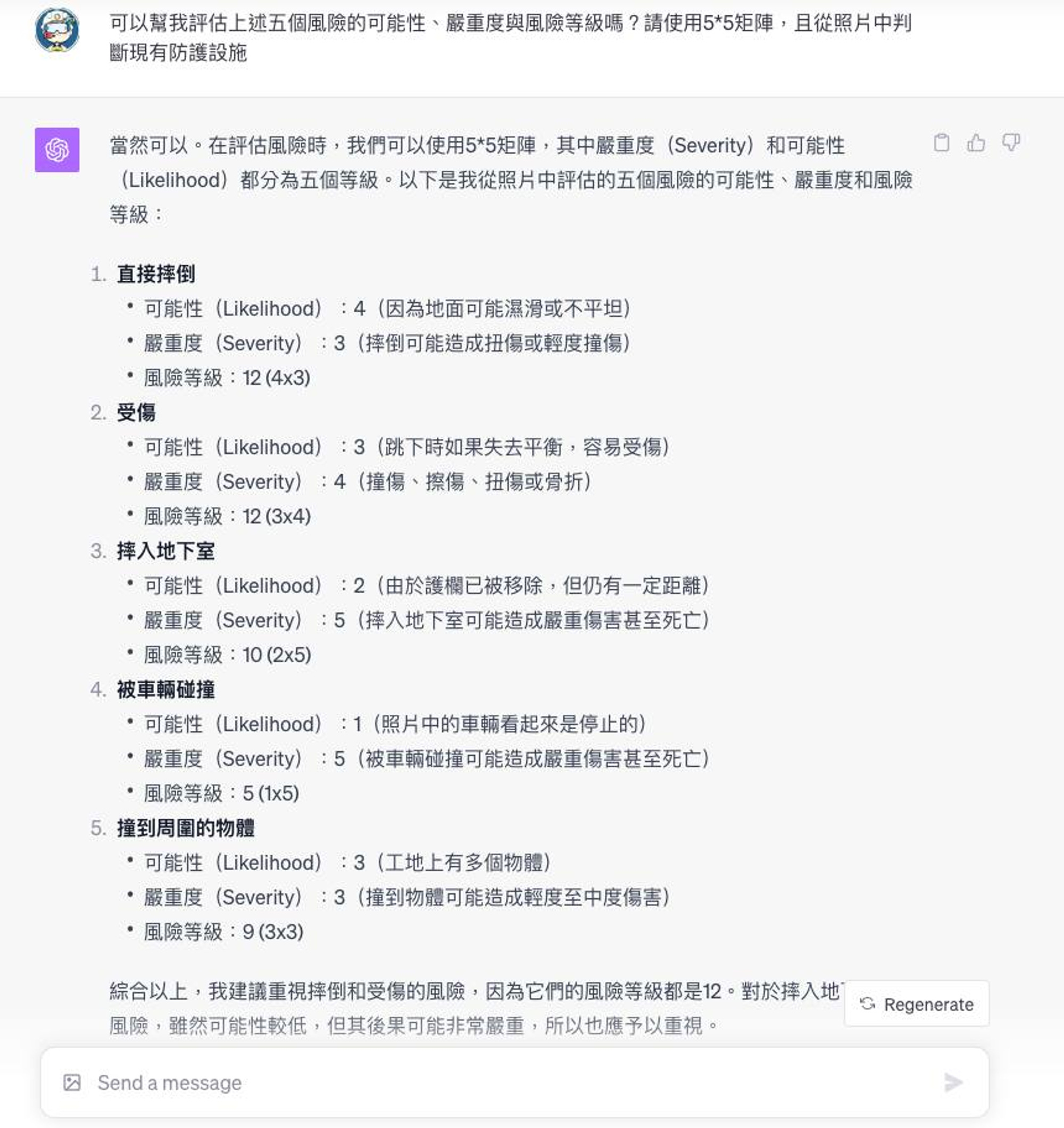
我們在這裏節錄 Alan Lee 大大所公佈的實做說明:營造安全GPT的相關問題回覆 感受到大家對於GPT的熱情,我綜合回覆一下相關問題。 1. 首先是這個GPT是怎麼做的? ChatGPT提供讓創作者開發的功能,其中一個用法就是將原本很複雜的對話過程,簡化成使用者僅需要提供一張照片或一個訊息,其他指令就會自動完成。 以我上一個GPT為例,我讓GPT辨識上傳照片的內容,找出現有防護措施以及可能存在的風險,並用5X5的風險矩陣進行風險評估,且利用法規資料庫與網路資料,提供風險消除、風險替代、工程控制、管理控制、個人防護具的建議。最後根據追加的風險處理對策進行風險再評估。 對使用者來說,不用知道這些過程,只需要拍照就好了。是不是很方便! 2. 怎麼使用這些GPT? 目前我僅將連結發送給幾個測試中的工地,以進行使用者意見的回饋與相關研究。待調整後會上架至GPT Store,提供給大家使用。 3. 還有其他GPT嗎? 我還做了法規鑑別GPT、風險評估GPT、ESG-GPT等,隨後再陸續跟大家介紹。 4. 怎麼提高GPT的使用能力? 如果大家對於提高GPT能力有興趣者,可以參考以下指引所提的六大策略,以獲得更滿意的回覆。 <https://platform.openai.com/....../prompt-engineering>......
最後,如果你也想實際使用看看,很感謝 Alan Lee 大大在我們週報正式發佈前,正式公開讓我使用。 營造工安 GPTs 的網址在這: https://chat.openai.com/g/g-WlF2suAw6-ying-zao-an-quan-gpt
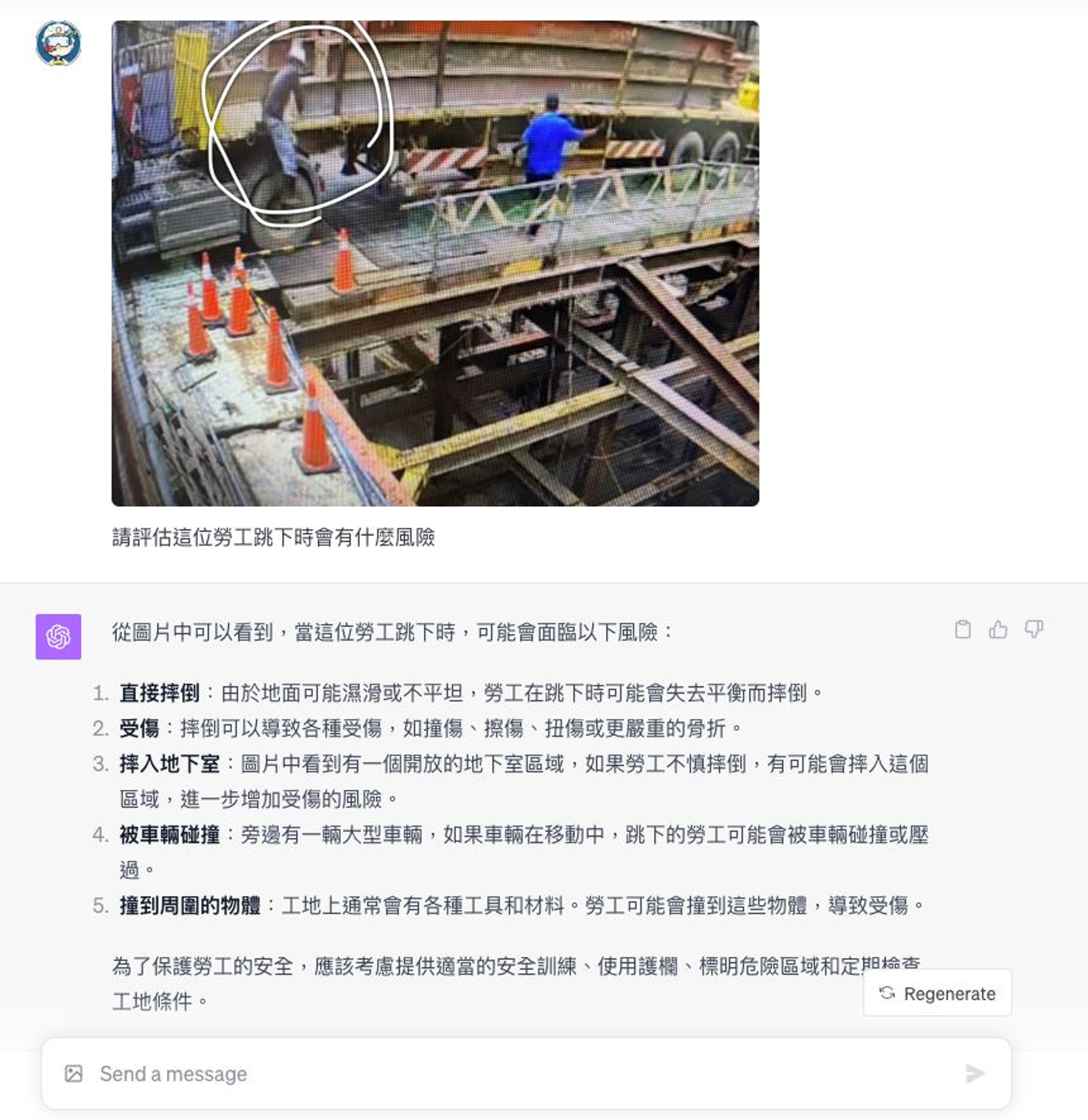


精彩文章(論文)分享
微軟開源了一個完整的 LLM 評估框架,原始論文: [2312.07910v1] PromptBench: A Unified Library for Evaluation of Large Language Models (arxiv.org)
論文導讀 & 摘要
PromptBench區別於其他框架,如LangChain、LlamaIndex和eval-harness,因為它提供了一個更全面和統一的評估大型語言模型(LLMs)的方法。這些現有的框架雖然在各自的領域內有所貢獻,但它們並未全面涵蓋LLMs的評估需求。以下是對PromptBench的獨特性和全面性的詮釋: 對比其他框架: LangChain和LlamaIndex:這些框架主要集中於提供整個LLM管道的實現,用於各種下游應用。它們通過整合數據庫和各種數據源來增強LLM應用,實現高級的、上下文感知的功能。然而,它們並非專門為評估目的而設計。 Semantic Kernel:旨在將AI服務與編程語言融合,用於多功能AI應用開發,但同樣不專注於LLMs的評估。 Eval-harness:提供了一個全面的生成語言模型評估框架,但不支持如對抗性提示攻擊、提示工程和動態評估等其他評估。 PromptBench的全面性: 綜合評估:PromptBench是一個統一的Python庫,專門用於從全面的維度評估LLMs。它包括了廣泛的LLMs和評估數據集,涵蓋了多種任務、評估協議、對抗性提示攻擊和提示工程技術。 模塊化設計:其模塊化的設計使研究人員能夠輕鬆構建適合自己項目的評估管道。 分析工具:支持多種分析工具,幫助研究人員解釋結果。 開源和協作:提供全面的文檔和教程,支持易用、靈活和協作的評估。 總結來說,PromptBench提供了一個全面、統一且專門針對LLMs評估的解決方案,這在其他現有框架中是缺乏的。它不僅支持標準的評估方法,還包括對抗性提示攻擊、提示工程和動態評估等先進功能,從而使研究人員能夠更全面地理解和評估LLMs的能力。如果對這論文想要更深入探討它所包含的內容,可以參考以下的中文 youtube 影片:
promptbench:微软发布评估大型语言模型LLMs性能的框架,可评测不同数据集、不同提示词、不同任务等在不同大模型下的表现,可用于llm应用基座选择场景 - YouTube
總結
在本期的週報中,我們深入探討了多個關於 GPTs 的應用和評估工具。從“OpenAI 官方提示工程指南”的詳細註釋開始,我們了解了如何清晰地撰寫指令,以及如何明確指出完成任務所需的步驟、提供範例,以及指定期望的輸出長度。
我們也聚焦於一個具啟發性的案例:在營造業中運用 GPTs 進行工安提醒和分析。這個案例不僅展示了 GPTs 深度應用的可能性,也展現了原作者對於分享知識和經驗的熱情。
此外,我們介紹了微軟開源的全面 LLM 工具庫,提供了一個統一的平台來評估大型語言模型的性能。我們還推薦了一部詳細介紹這個工具庫的中文 YouTube 影片,為想要全面理解這一工具的讀者提供了一個極佳的學習資源。
希望本期週報的內容能滿足您的需求。