ChatGPT 跨界應用週報(第八期)
從 OpenAI 學習到 ChatGPT 實務應用

本週精彩圖表
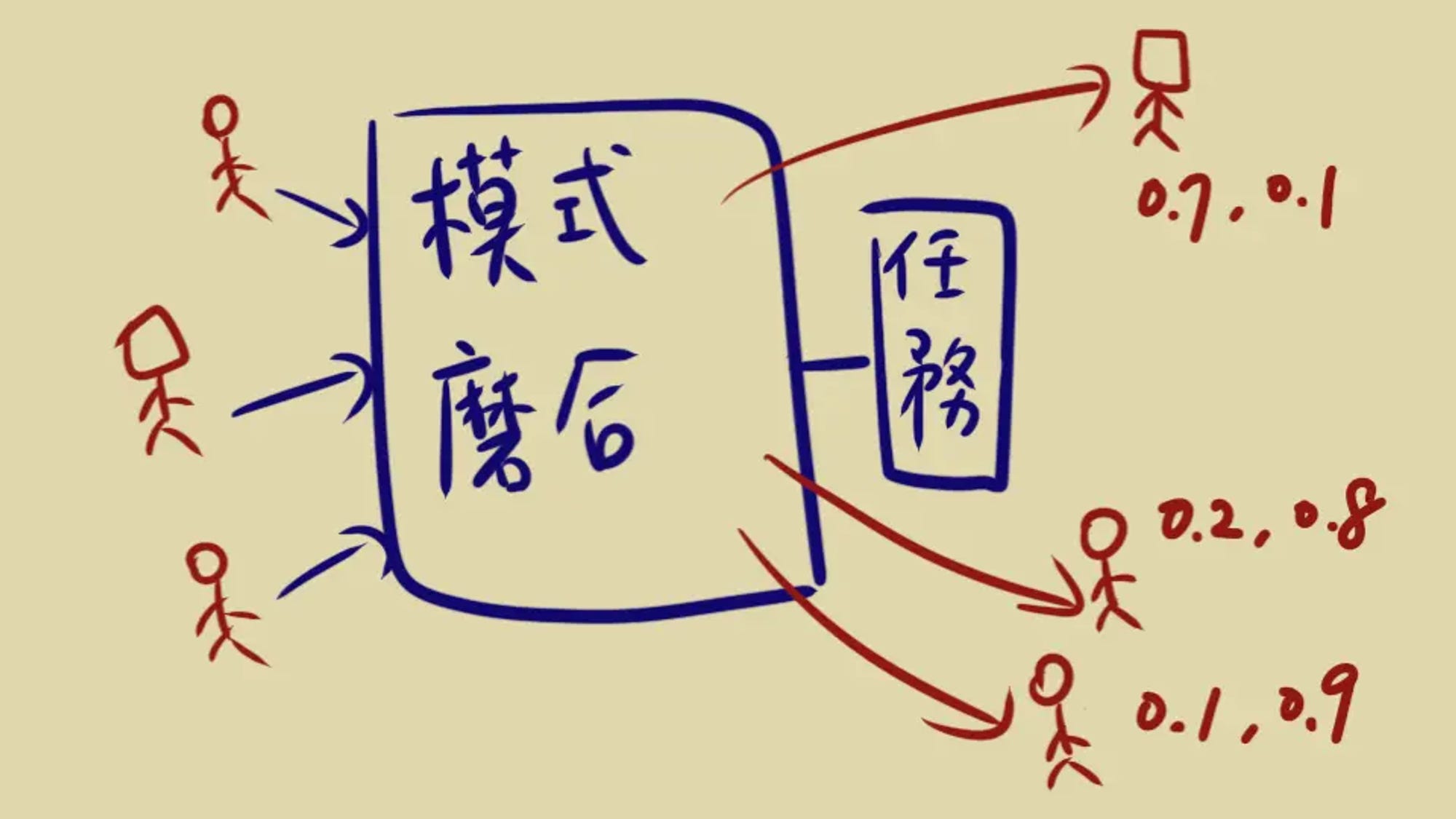
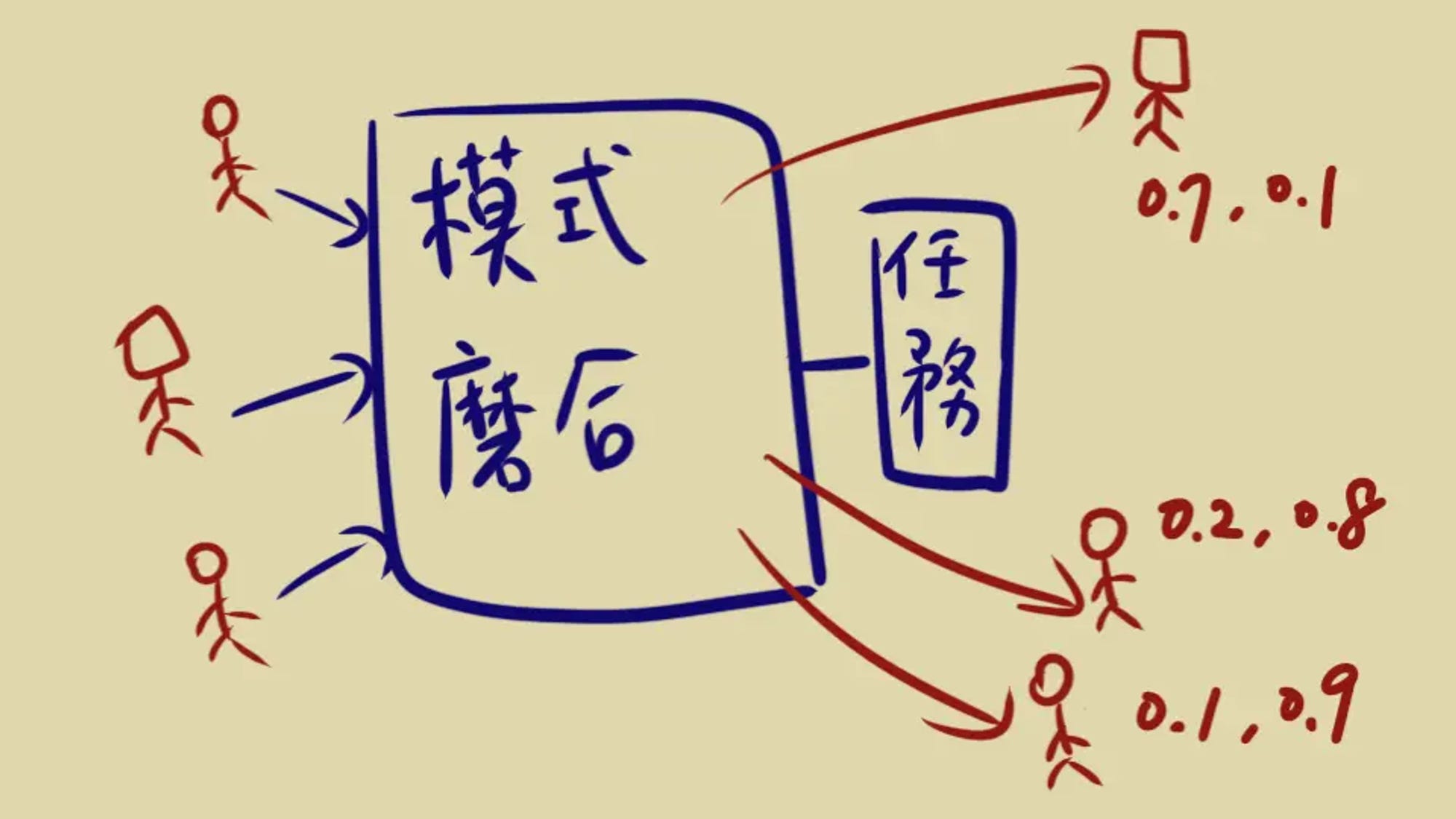
(資料來源: 白話文告訴你 - 什麼是 Embedding)
本期內容
OpenAI 官方提示工程指南 - 註釋
提示技巧 4-2:使用內心獨白或一系列查詢隱藏模型的推理過程
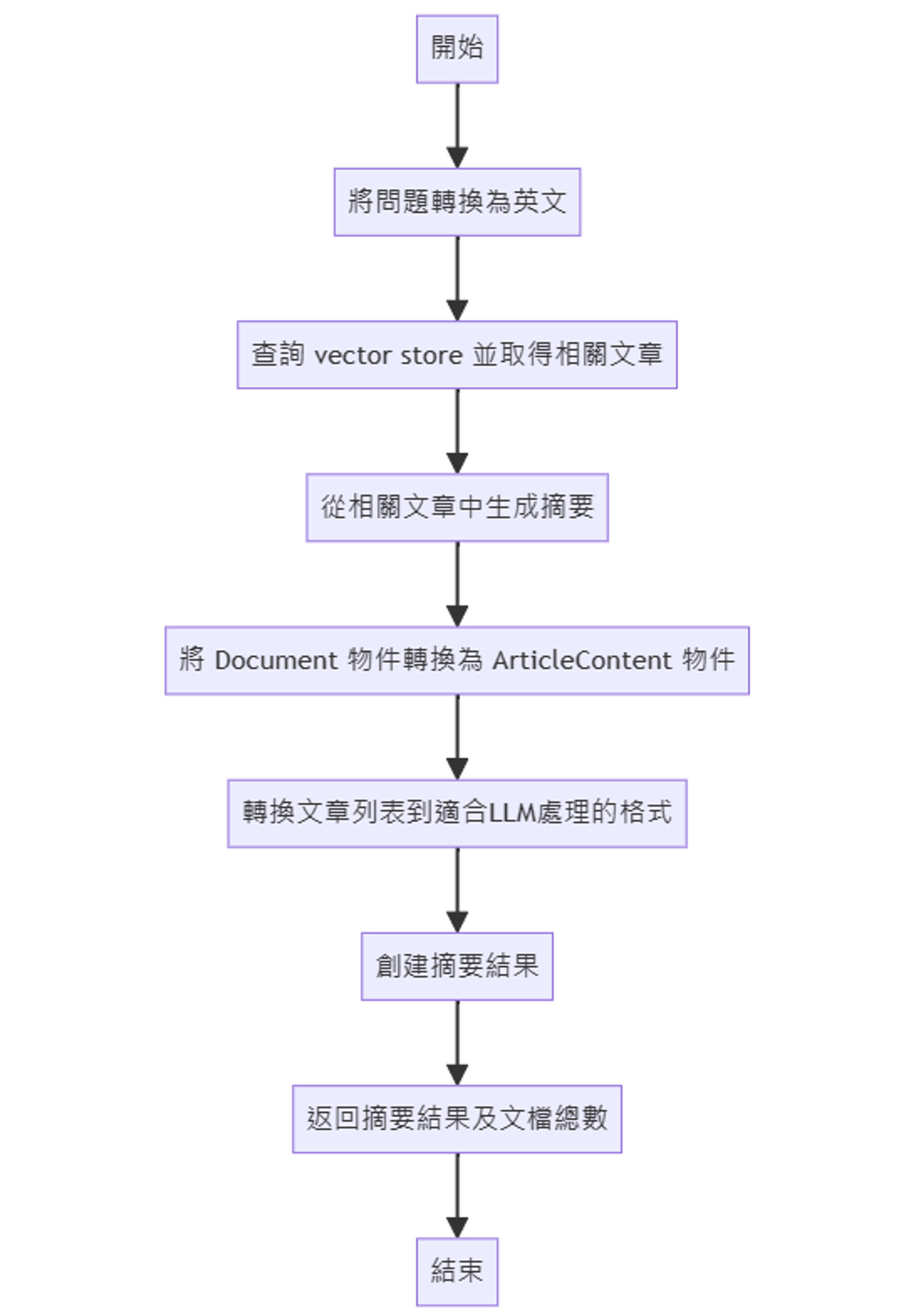
大型語言模型應用介紹
Code to Diagram GPTs
精彩文章(論文)分享
白話文告訴你 - 什麼是 Embedding
企業級 RAG(檢索增強生成)系統開發的實踐過程系列 – 什麼是 RAG?
OpenAI 官方提示工程指南 - 註釋
(此段落為 OpenAI 官方提示工程指南的註釋,原文請參考: Prompt engineering - OpenAI API)
提示技巧 4-2:使用內心獨白或一系列查詢隱藏模型的推理過程 前一個策略展示了有時候對於模型來說,在回答一個具體問題之前詳細地推理一個問題是重要的。對於某些應用來說,模型用來得出最終答案的推理過程如果與用戶分享,可能是不適當的。例如,在輔導應用中,我們可能想鼓勵學生自己解答問題,但模型對學生解答的推理過程可能會透露給學生答案。 內心獨白是一種可以用來緩解這個問題的策略。內心獨白的想法是指示模型將意味著要從用戶隱藏的輸出部分放入一種結構化的格式,使得解析它們變得容易。然後在向用戶展示輸出之前,解析輸出並僅使輸出的一部分可見。
提示範例:System 遵循以下步驟來回答使用者查詢。 步驟1 - 首先提出解決問題的你自己的解決方案。不要依賴學生的解決方案,因為它可能是不正確的。將這一步的所有工作放在三引號(""")內。 步驟2 - 比較你的解決方案和學生的解決方案,評估學生的解決方案是否正確。將這一步的所有工作放在三引號(""")內。 步驟3 - 如果學生犯了錯誤,確定你可以給學生什麼提示而不透露答案。將這一步的所有工作放在三引號(""")內。 步驟4 - 如果學生犯了錯誤,提供上一步的提示給學生(在三引號外)。不要寫“步驟4 - ...”,而是寫“提示:”。 User 問題陳述:<插入問題的描述> 學生解決方案:<插入學生的解答方案>除了以上的方式,我們也可以通過一系列查詢來實現,在這些查詢中,除了最後一個之外,所有的輸出都對終端使用者隱藏。
首先,我們可以要求模型自己解決問題。由於這個初始查詢不需要學生的解答,因此可以省略。這提供了額外的優勢,即模型的解決方案不會因學生的嘗試解答而有偏差。
例如以下提示,我們直接將問題交給語言模型來做解答:
User <插入問題的描述>接下來,我們可以讓模型使用所有可用的信息來評估學生解答的正確性:
System 比較你的解決方案和學生的解決方案,評估學生的解決方案是否正確。 User 問題陳述:"""<插入問題的描述>""" 你的解決方案:"""<插入上個步驟語言模型產生的解決方案>""" 學生的解決方案:"""<插入學生的解答方案>"""最後,我們可以讓模型使用自己的分析來構建一個回覆,在這個回覆中扮演一個有幫助的導師的角色。
System 你是一位數學導師。如果學生犯了錯誤,以一種不透露答案的方式給學生一個提示。如果學生沒有犯錯,簡單地給他們一個鼓勵的評語。 User 問題陳述:"""<插入問題的描述>""" 你的解決方案:"""<插入語言模型產生的解決方案>""" 學生的解決方案:"""<插入學生的解答方案>""" 分析:"""<插入上個步驟語言模型產生的分析資訊>"""以上提示技巧的概念,我們舉一個教學場域上的例子來說明它的含義:

想像一下,你是一位在班上協助學生解救數學難題的老師。一名學生對於某個特定的數學問題感到困惑,而你知道直接給出答案不會真正幫助學生學習和理解概念。所以,你決定採取一種更巧妙的方法來引導學生自己找到答案。 首先,你自己心裡默默地解答問題,這就像是你的內心獨白,你不會直接告訴學生這個過程。接著,你比較學生提供的解答和你自己的解答,但你仍然保持這個比較過程只在你心中進行。 如果發現學生犯了一個錯誤,你會思考一個不透露正確答案的方式來給出提示。例如,你可能會問:“你有沒有檢查過你的乘法步驟?”或者“你能找到這個方程式中的另一種解法嗎?”這樣的問題旨在引導學生自己思考和解決問題,而不是直接給出答案。 這種策略就像是一個隱形的手,輕輕引導學生朝著正確的方向前進,而不是把答案直接放在他們面前。透過這種方式,學生不僅能找到答案,還能學習到解決問題的過程,這是真正的學習和理解。大型語言模型應用介紹
Code to Diagram GPTs
最近發現了一個頗有趣的 GPTs,和大家分享。它能自動分析程式碼並轉換成易懂的Mermaid圖表。至於這樣的功能可能有什麼用途呢? 以下表列了幾個可能的使用情景:程式碼審查和優化: 在審查過程中快速生成流程圖,幫助團隊理解邏輯,找出錯誤和優化點,促進有效溝通。
新成員培訓: 提供清晰的架構圖,幫助新成員快速瞭解項目結構,提升學習效率。
系統文件維護: 隨著專案的進展,自動更新系統架構圖和流程圖,減少手動工作量,確保文件與實際程式碼同步。
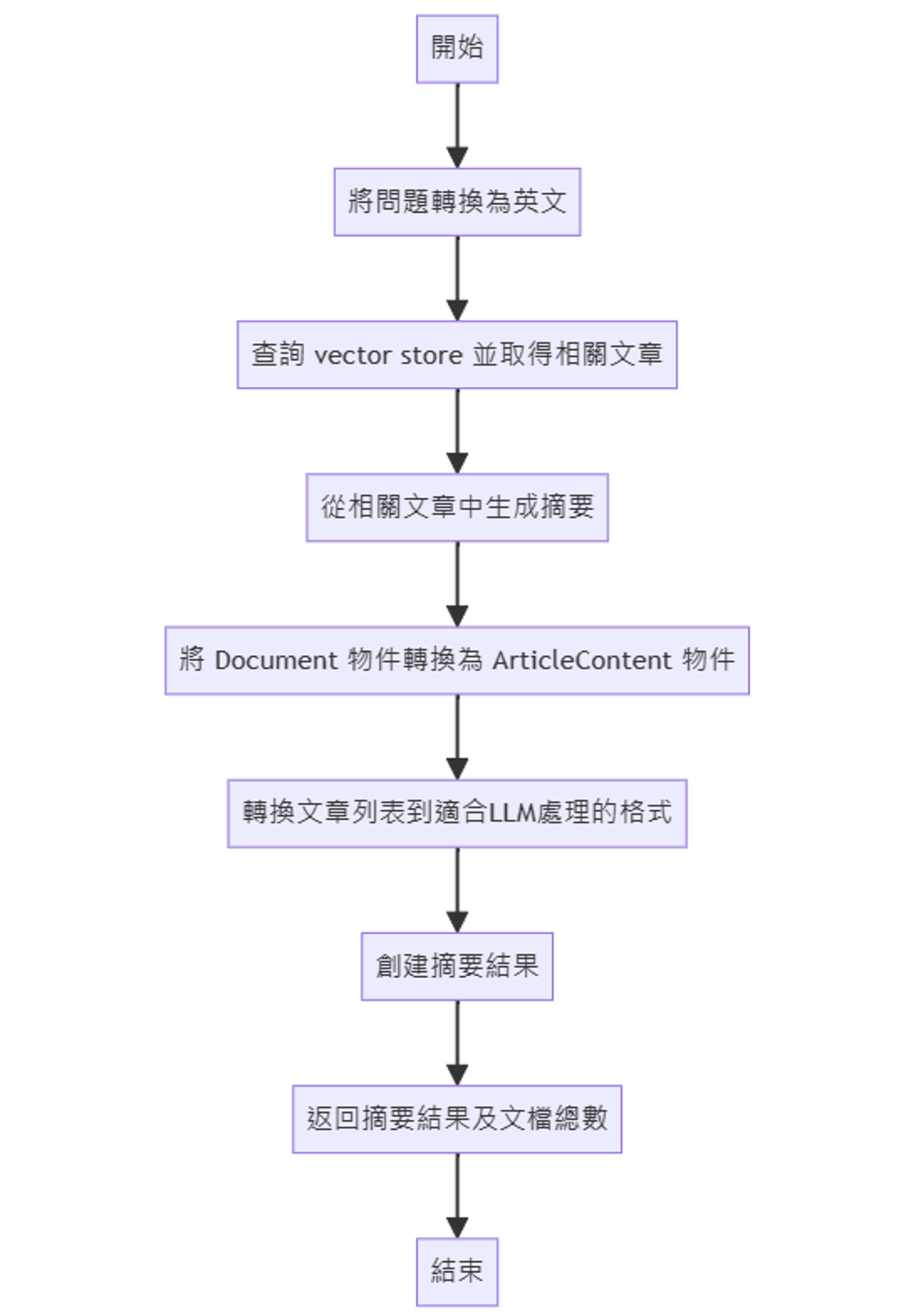
使用方式:
將你的程式碼貼到 Code to Daigram GPTs, 讓它幫你產生 mermaid 的 Markdown 語法。
將產生的 diagram code, 貼到 mermaid 服務上即可。
精彩文章(論文)分享
白話文告訴你 - 什麼是 Embedding
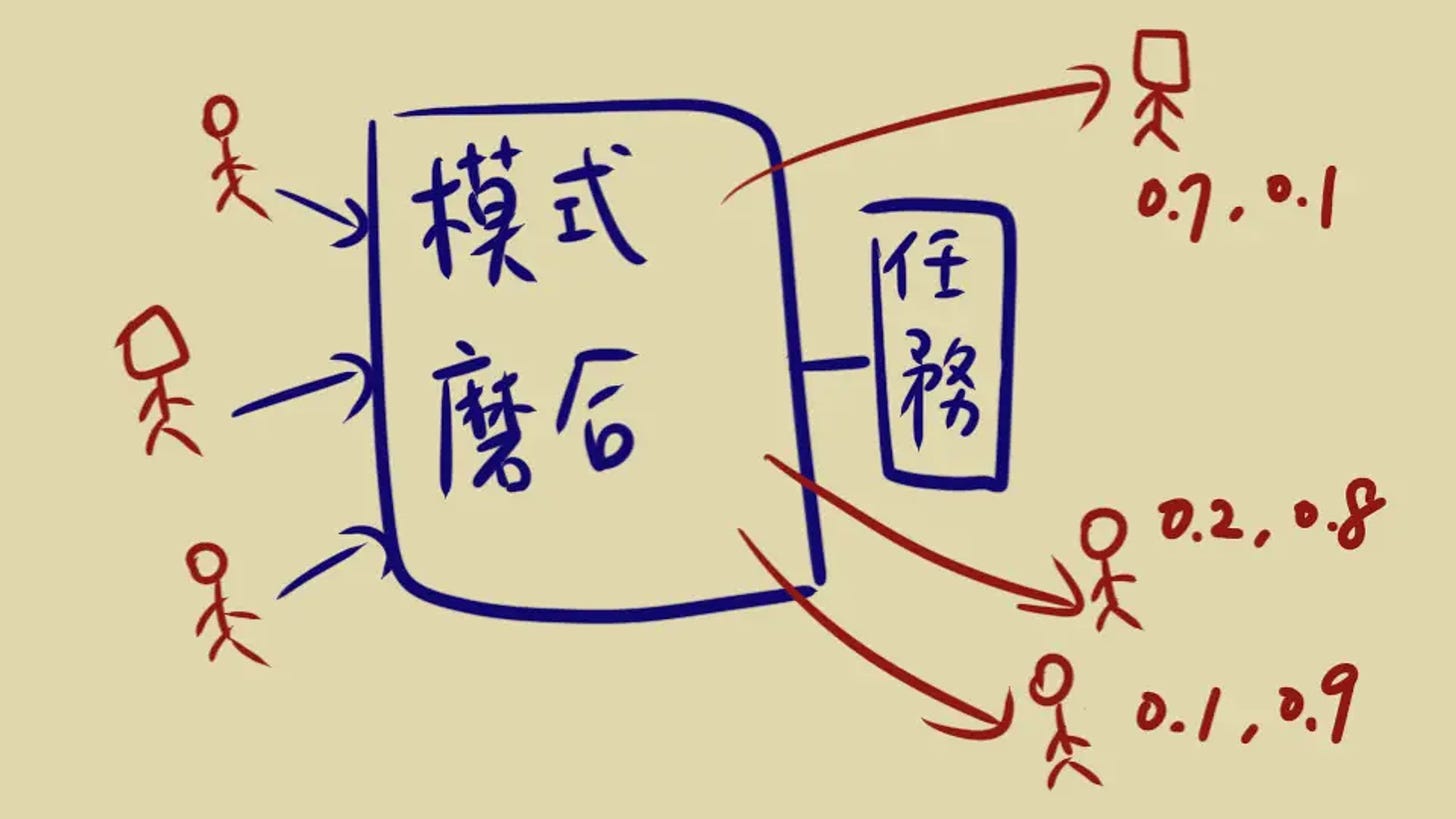
內容簡介
這篇文章以一種淺顯易懂的方式解釋了什麼是 Embedding。Embedding 是機器學習和人工智能中一個重要的概念,它將每樣東西轉化成一串數字向量來代表。這些數字向量之間的相似性表示了這些事物本身的相似性。文章通過生活中的比喻,如高中新生形成小團體和新創公司試用新員工的過程,來解釋這個概念。這些比喻說明了要形成有效的 Embedding,需要有一個「共同的任務」。技術上來講,Embedding 或者向量化(如 xxx2vec)可以將圖片、文字、句子等轉化為數字序列,這些數字序列便於進行各種運算,從而實現推薦、分類等應用。Embedding 的生成是通過某種類神經網路模型在完成特定任務(如分類或預測)的過程中「學習」出來的,不是隨意指定的。 以白話解釋: 想象一下,你剛進入一個全新的班級,起初你不認識任何人。隨著時間的推移,你通過參與各種活動(這裡的「共同任務」),慢慢地與一些同學建立起了特殊的關係,形成了一個小團體。同理,如果你是一家新創公司的老板,在試用期間,你會觀察新員工是否與公司文化和團隊成員臭味相投。這個過程中,你並沒有使用任何明確的數值或特徵來評估這些關係,但你仍然能夠感覺到誰與誰更相近。 在機器學習中,Embedding 也是這樣一個過程。它不是用一些直觀的數據(如年齡、身高等)來描述事物,而是通過學習過程中的「共同任務」來捕捉事物之間微妙的相似性或關聯性。這些被轉化成的數字向量,雖然我們不能直接解釋它們代表什麼,但它們能夠有效地表達事物之間的相似度。就像你能感覺到哪些同學是你的「圈子」一樣,機器透過 Embedding,也能「感覺到」數據之間的關聯性。
企業級 RAG(檢索增強生成)系統開發的實踐過程系列 – 什麼是 RAG?
原文網址: 企業級 RAG(檢索增強生成)系統開發的實踐過程系列 - 什麼是 RAG? - Botsnova official blog
內容簡介:
當我們談論到使人工智慧模型更加智能和實用的技術時,檢索增強生成(Retrieval-Augmented Generation,簡稱RAG)無疑是一項引人注目的創新。我最近讀到了一篇非常精彩的文章,它不僅清晰地解釋了RAG是什麼,還深入探討了它的來源、定義以及簡史,使得這個複雜的主題變得易於理解。 文章的作者以圖書館員和讀者之間的互動為比喻,生動地描繪了RAG如何工作。就像圖書館員幫助讀者在廣闊的書海中找到所需的知識一樣,RAG允許大型語言模型(LLM)通過從外部資料源檢索資訊來提高對特定查詢的回答質量和準確性。這種方法不僅拓展了LLM的知識範圍,也讓它能夠提供更加豐富和精確的回應。 文章還介紹了RAG命名的有趣歷史背景,以及它如何成為提高生成式AI模型推論結果準確性和可靠性的一系列方法論的集合名詞。透過深入淺出的解釋和實例,讀者可以輕鬆地理解RAG的技術細節和其在自然語言處理領域的應用價值。 對於任何對人工智能、機器學習或自然語言處理感興趣的人來說,這篇文章都是一份寶貴的資源。它不僅提供了RAG的全面概覽,還突出了這項技術對於未來AI發展的重要性。無論你是AI領域的專家還是剛入門的學習者,這篇文章都值得一讀。