
ChatGPT 跨界應用週報(第九期)
從 OpenAI 學習到 ChatGPT 實務應用

本週精彩圖表

本期內容
OpenAI 官方提示工程指南 - 註釋
提示技巧 4-3:詢問模型是否在先前的處理中遺漏了什麼
大型語言模型應用介紹
六個可以將 “圖形代碼” 轉換為漂亮圖表的應用程式介紹
精彩文章(論文)分享
生成式 AI 設計模式:全面指南
OpenAI 官方提示工程指南 - 註釋
(此段落為 OpenAI 官方提示工程指南的註釋,原文請參考: Prompt engineering - OpenAI API)
提示技巧 4-3:詢問模型是否在先前的處理中遺漏了什麼
假設我們正在使用一個模型從某個來源中選出與特定問題相關的摘錄。在列出每個摘錄後,模型需要判斷是否應該開始撰寫另一個摘錄或者停止。如果來源文件很大,模型通常會過早停止,未能列出所有相關的摘錄。在這種情況下,通過使用後續查詢來提示模型找出之前遺漏的摘錄,往往可以獲得更好的性能。
以下為提示範例:SYSTEM 你將獲得一個由三重引號分隔的文件。你的任務是選擇與以下問題相關的摘錄:"人工智能歷史上發生了哪些重大的範式轉變。" 確保摘錄包含解釋它們所需的所有相關上下文,換句話說,不要提取缺少重要上下文的小片段。按以下 JSON 格式提供輸出: [{"excerpt": "..."}, ... {"excerpt": "..."}] USER """<在這裏插入文檔內容>""" ASSISTANT [{"excerpt": "模型在這裡寫下一個摘錄"}, ... {"excerpt": "模型在這裡寫下另一個摘錄"}] USER 還有更多相關的摘錄嗎?注意不要重複摘錄。同時確保摘錄包含解釋它們所需的所有相關上下文——換句話說,不要提取缺少重要上下文的小片段。(實際的範例程式碼,可以參考 OpenAI Playground 範例,鏈接在這裏: default-2nd-pass)
還有哪些類似使用案例?教育領域 - 用於幫助學生理解文學作品中的主題或符號:
SYSTEM 你將獲得一篇由三重引號分隔的文學作品。你的任務是選擇與以下問題相關的摘錄:"這部作品中的主要主題和符號是什麼?" 確保摘錄包含足夠的上下文以便於解釋,換句話說,不要提取缺少重要上下文的小片段。按以下 JSON 格式提供輸出: [{"excerpt": "..."}, ... {"excerpt": "..."}] USER """<在這裏插入文學作品內容>""" ASSISTANT [{"excerpt": "模型在這裡寫下一個摘錄"}, ... {"excerpt": "模型在這裡寫下另一個摘錄"}] USER 還有更多相關的摘錄嗎?注意不要重複摘錄。同時確保摘錄包含足夠的上下文以便於解釋。市場研究 - 用於從消費者評論或市場報告中提取關鍵見解:
SYSTEM 你將獲得一系列由三重引號分隔的消費者評論。你的任務是選擇與以下問題相關的摘錄:"消費者對我們的新產品有哪些正面和負面的反饋?" 確保摘錄包含足夠的上下文以便於解釋,換句話說,不要提取缺少重要上下文的小片段。按以下 JSON 格式提供輸出: [{"excerpt": "..."}, ... {"excerpt": "..."}] USER """<在這裏插入消費者評論內容>""" ASSISTANT [{"excerpt": "模型在這裡寫下一個摘錄"}, ... {"excerpt": "模型在這裡寫下另一個摘錄"}] USER 還有更多相關的摘錄嗎?注意不要重複摘錄。同時確保摘錄包含足夠的上下文以便於解釋。技術文件分析 - 用於從技術文件或使用手冊中提取操作指南或重要特性:
SYSTEM 你將獲得一個由三重引號分隔的技術文件。你的任務是選擇與以下問題相關的摘錄:"這個設備的主要功能和操作指南是什麼?" 確保摘錄包含足夠的上下文以便於解釋,換句話說,不要提取缺少重要上下文的小片段。按以下 JSON 格式提供輸出: [{"excerpt": "..."}, ... {"excerpt": "..."}] USER """<在這裏插入技術文件內容>""" ASSISTANT [{"excerpt": "模型在這裡寫下一個摘錄"}, ... {"excerpt": "模型在這裡寫下另一個摘錄"}] USER 還有更多相關的摘錄嗎?注意不要重複摘錄。同時確保摘錄包含足夠的上下文以便於解釋。

大型語言模型應用介紹
六個可以將 “圖形代碼” 轉換為漂亮圖表的應用程式介紹
上周剛好跟各位朋友們分享了【Code to Diagram】GPTs,一個能將你的程式碼轉換成 Mermaid 語法的工具。實際上,這種能夠通過文本定義圖表的工具並不罕見。本周我偶然看到一個影片,介紹了六個知名的轉換工具/服務。對這類工具感興趣的朋友不妨一探究竟。

精彩文章(論文)分享
生成式 AI 設計模式:全面指南
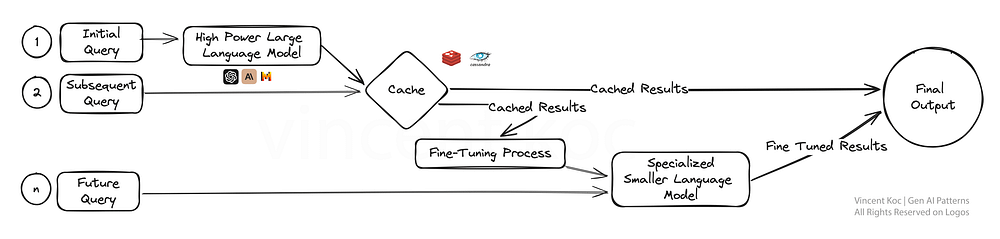
這篇文章簡要介紹了九種生成式AI系統中常見的設計模式。雖然對細節的描述不多,但提供的圖表既全面又精緻,非常值得參考。此外,我先在此幫大家列出各設計模式的可能應用場景,想要深入了解的讀者可以參閱原文。
分層緩存策略導致細微調整(Layered Caching Strategy Leading To Fine-Tuning):這一策略通過緩存大型語言模型的初步結果,快速回應後續查詢,提高效率。隨著數據積累,進行細微調整以根據用戶反饋優化模型,特別適合需要快速響應的應用場景,如客戶服務和個性化內容創建。
多路復用AI代理組成專家小組(Multiplexing AI Agents For A Panel Of Experts):這種模式通過多個專業領域的AI代理并行工作,集合不同專家的答案來解決問題,適用於需要從多角度考慮的複雜問題解決,如跨學科的研究或綜合性決策制定。
針對多項任務細微調整LLM(Fine-Tuning LLM’s For Multiple Tasks):通過對一個大型語言模型同時進行多任務的細微調整,提高跨領域的知識轉移和技能適用性,適用於虛擬助理或AI驅動的研究工具,需要處理多種類型任務的平台。
混合規則基礎和生成式(Blending Rules Based & Generative):將創造性的生成式AI與規則基礎的邏輯結合,產生既符合規範又不失創新的解決方案,特別適合於需要嚴格遵守標準或規範的行業,如金融服務或健康護理。
利用知識圖論結合LLM(Utilizing Knowledge Graphs with LLM’s):結合知識圖論使AI模型能夠提供更加準確和事實正確的輸出,適用於對真實性和準確性要求極高的應用,如教育內容創建、醫療建議或新聞報導。
生成式AI代理群(Swarm Of AI Agents):模仿自然界中的群體行為,通過多個AI代理集體解決問題,適用於需要廣泛創意解決方案或處理複雜數據集的場景,如創意寫作、設計或數據分析。
模塊化單體LLM方法與可組合性(Modular Monolith LLM Approach With Composability):這種設計允許AI系統根據需要動態重組,以最有效地完成任務,類似於可根據需求更換工具的瑞士軍刀,適合需要定制解決方案的業務,如客戶互動或產品開發。
針對LLM的記憶認知方法(Approach To Memory Cognition For LLM’s):通過引入類似人類記憶的機制,讓AI模型能夠記憶並利用過去的互動來提供更加精確的回應,適用於需要長期互動和學習的應用,如個性化學習平台或客戶服務。
紅藍對抗雙模型評估(Red & Blue Team Dual-Model Evaluation):這種模式通過一個AI模型生成內容,另一個AI模型進行批判性評估,以提高內容質量,適用於內容生成平台,需要確保內容的可信度和準確性,如新聞聚合或教育材料生產。
