ChatGPT 跨界應用週報(第六期)
從 OpenAI 學習到 ChatGPT 實務應用

本週精彩圖表
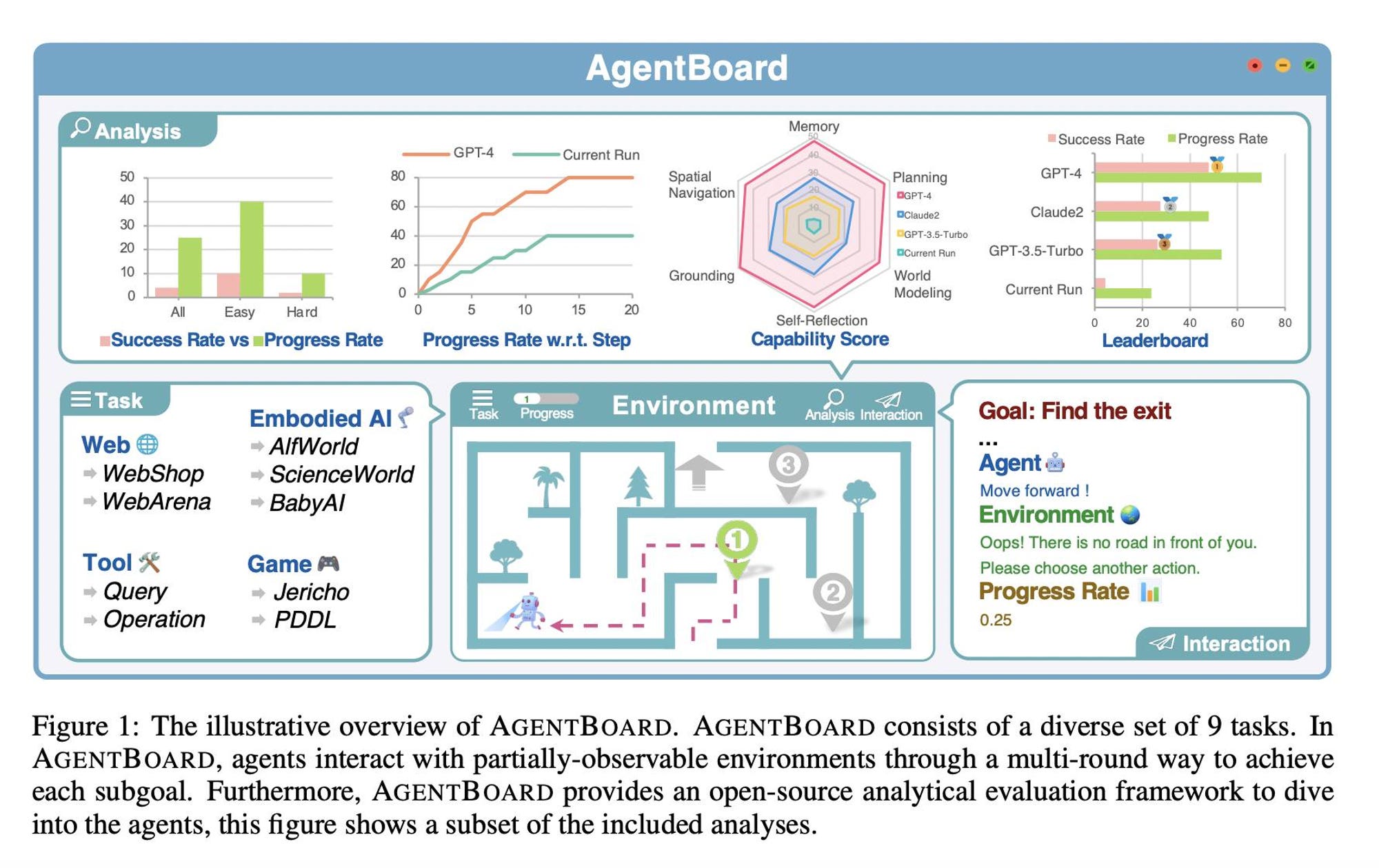
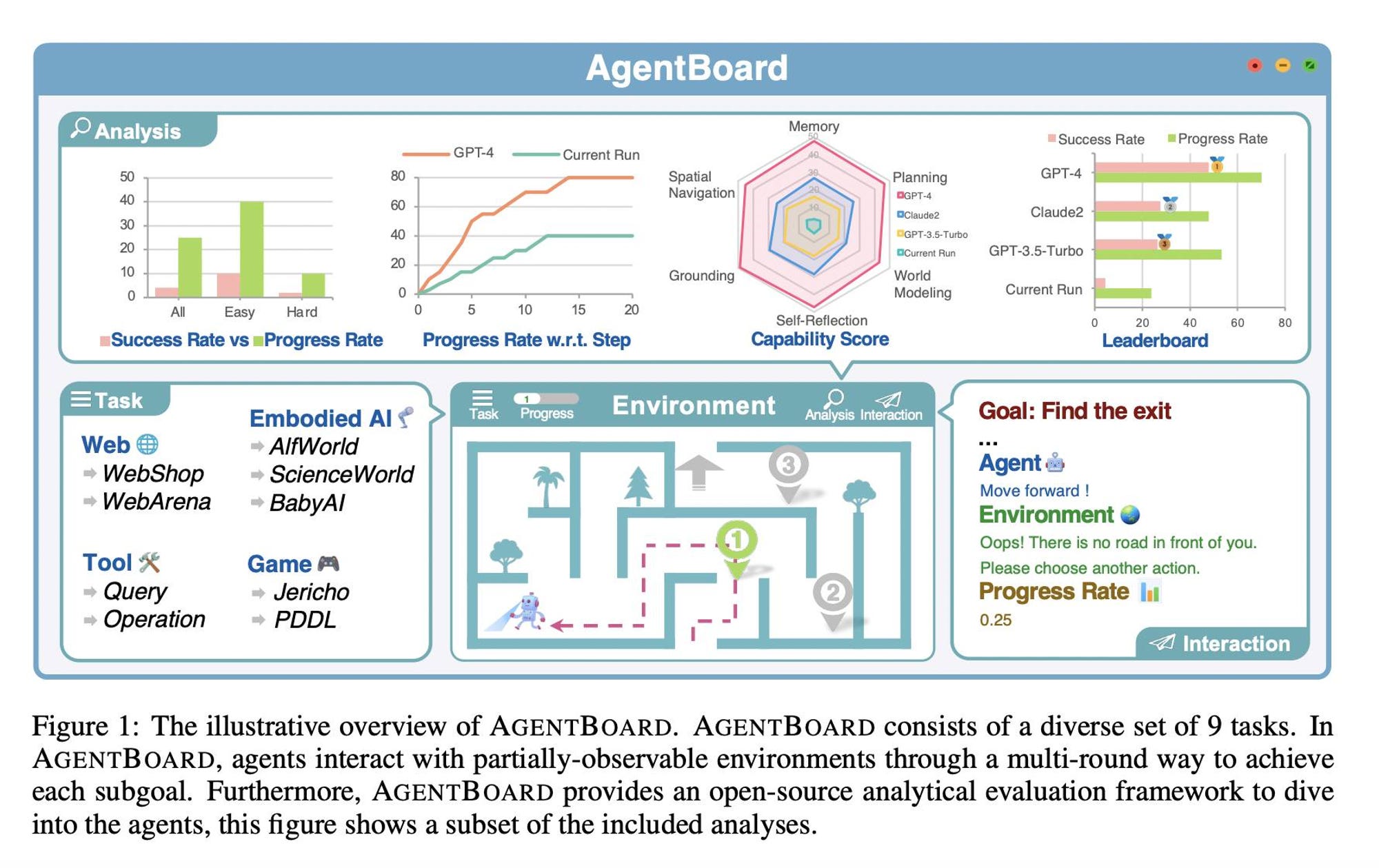
(資料來源: AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents)
編輯的話
過去一年,我對大型語言模型在未來產業中可能帶來的革命性創新充滿信心,因此我投入了所有的業餘時間來深入理解並推廣這一技術。
最初,對它的信心不過是出於直覺,但在見證了安德魯小舖GPTs的概念驗證(POC)應用,以及原作者對他的實作過程的詳盡分享之後,我對大型語言模型,特別是GPTs(AI Agent)的應用潛力有了更深的認識和堅定的信念。
而這正是我們特意為 GPTs 開發設計了「從教材生成,學習GPTs開發」這門課的原因。
在本期的特別推薦中,我強烈建議大家親自嘗試並細讀我們分享的安德魯小舖 GPTs 應用案例。
最後,祝大家新年快樂,讓我們一同迎接充滿希望以及將大型語言模型應用實際落地的2024年!
本期內容
OpenAI 官方提示工程指南 - 註釋
提示技巧 3-3: 分段摘要長文檔並遞歸構建完整摘要
大型語言模型應用介紹
安德魯小舖 GPTs & 實做歷程分享
「從教材生成,學習GPTs開發」課程進行方式介紹
精彩文章(論文)分享
一個開源且適用於多元任務的 LLM Agent 的評估平台
OpenAI 官方提示工程指南 - 註釋
(此段落為 OpenAI 官方提示工程指南的註釋,原文請參考: Prompt engineering - OpenAI API)
提示技巧 3-3: 分段摘要長文檔並遞歸構建完整摘要
為了摘要一個非常長的文檔,例如一本書,我們可以使用一系列查詢來摘要文檔的每個部分。各部分的摘要可以被連接起來並摘要,產生摘要的摘要。這個過程可以遞歸進行,直到整個文檔被摘要。如果為了理解後面的部分而需要使用到前面部分的信息,那麼一個有用的技巧是在摘要該點內容時,包括一個運行摘要*,概述書中任何給定點之前的文本。OpenAI之前的研究已經使用 GPT-3 的變體研究了這個程序摘要書籍的有效性。
* 這裏所謂的“運行摘要”的意思這就像是: 我們在做筆記時,不僅記錄目前正在閱讀部分的內容,還會在旁邊備註一些之前章節的要點,這樣在閱讀和理解後續內容時就更加容易了。 OpenAI先前利用GPT-3的變體進行的研究表明,這種方法對於摘要長篇書籍是有效的。
舉例說明:在一個教學領域的應用中,教師可能需要對一本詳細的歷史教科書進行摘要,以便快速回顧或準備教學材料。首先,教師可以將教科書分成章節,對每個章節進行摘要。接著,這些章節摘要可以被進一步摘要,以形成對整本書的高層次概覽。如果某些章節相互之間有緊密聯繫,教師可以在摘要後面的章節時包括之前章節的運行摘要,以確保內容的連貫性。
大型語言模型應用介紹
安德魯小舖 GPTs & 實做歷程分享
我一直對GPT的發展抱持樂觀態度,相信以自然語言進行交流的用戶界面在未來將大放異彩。最近終於看到有人用充滿駭客精神的實作方式探索了這一概念的潛力,並開發了一個實驗性的概念驗證(POC)應用,以此來展示其潛在能力。(安德魯小舖GPTs)
這個POC應用挑戰的是,能否完全通過GPT來實現購物服務,甚至包括支付機制?
答案是,這確實是可行的!
具體是如何做到的呢?原作者在他的文章中提供了驗證過程的詳細說明:
[架構師觀點] 開發人員該如何看待 AI 帶來的改變? — 安德魯的部落格 (chicken-house.net)
操作過程截圖:
操作過程可以通過以下GPTs網址體驗:安德魯小舖 GPTs
消息來源: 愛好 AI Engineer 週報 🚀 Product Hunt 2023 年度最佳產品 #08 – ihower { blogging }

「從教材生成,學習GPTs開發」課程進行方式介紹
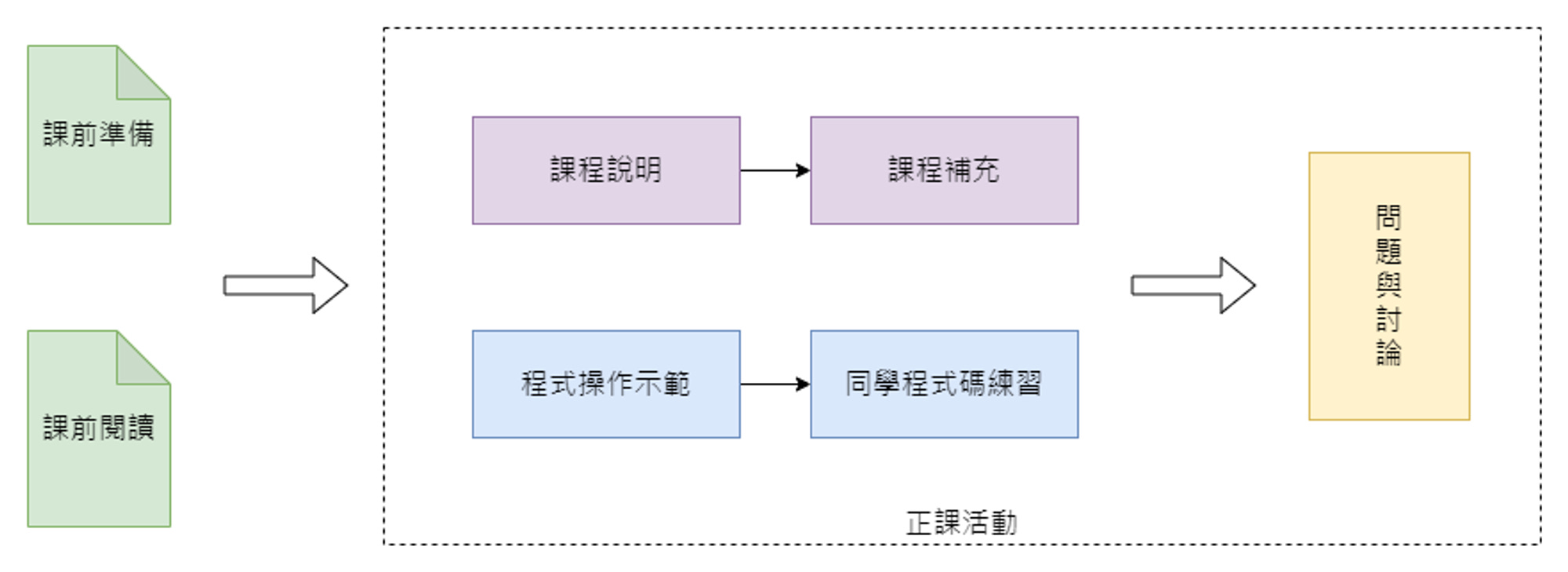
(「從教材生成,學習GPTs開發」課程進行方式)
在我們的分享會中,一位朋友提出了一個非常有趣的問題:如果我是個專案經理,但沒有Python程式的基礎,這門課程適合我嗎?
實際上,這門課程正是為專業經理人設計的技術入門課,旨在介紹必備的技術知識。即使您沒有 Python 程式的基礎,也不必擔心。我們提供了大量的 Colab 程式範例,並會在課堂上解釋重要的系統架構,引導學員理解關鍵的程式碼。當然,我們建議學員至少能夠理解,甚至輕鬆閱讀 Python 程式碼。
此外,我們採用引導式教學法進行課程,課前會提供學習資料以供自行閱讀,也會提出一些問題,促使大家在下一堂課中思考和討論。這樣的學習方式特別適合那些已經有具體目標想要實現的專業經理人、MIS 負責人,或是對 ChatGPT 及 OpenAI API 應用感興趣的教育工作者和專業玩家。
我們希望以上的介紹能夠幫助對這門課程有疑問的朋友們獲得更清楚的理解。
如果您也在考慮如何將大型語言模型的技術應用於工作或個人的業餘專案,並對此感興趣,歡迎查閱我們的正式招生簡章,以獲取更多訊息。
招生簡章: 「從教材生成,學習GPTs開發」招生簡章
精彩文章(論文)分享
一個開源且適用於多元任務的 LLM Agent 的評估平台
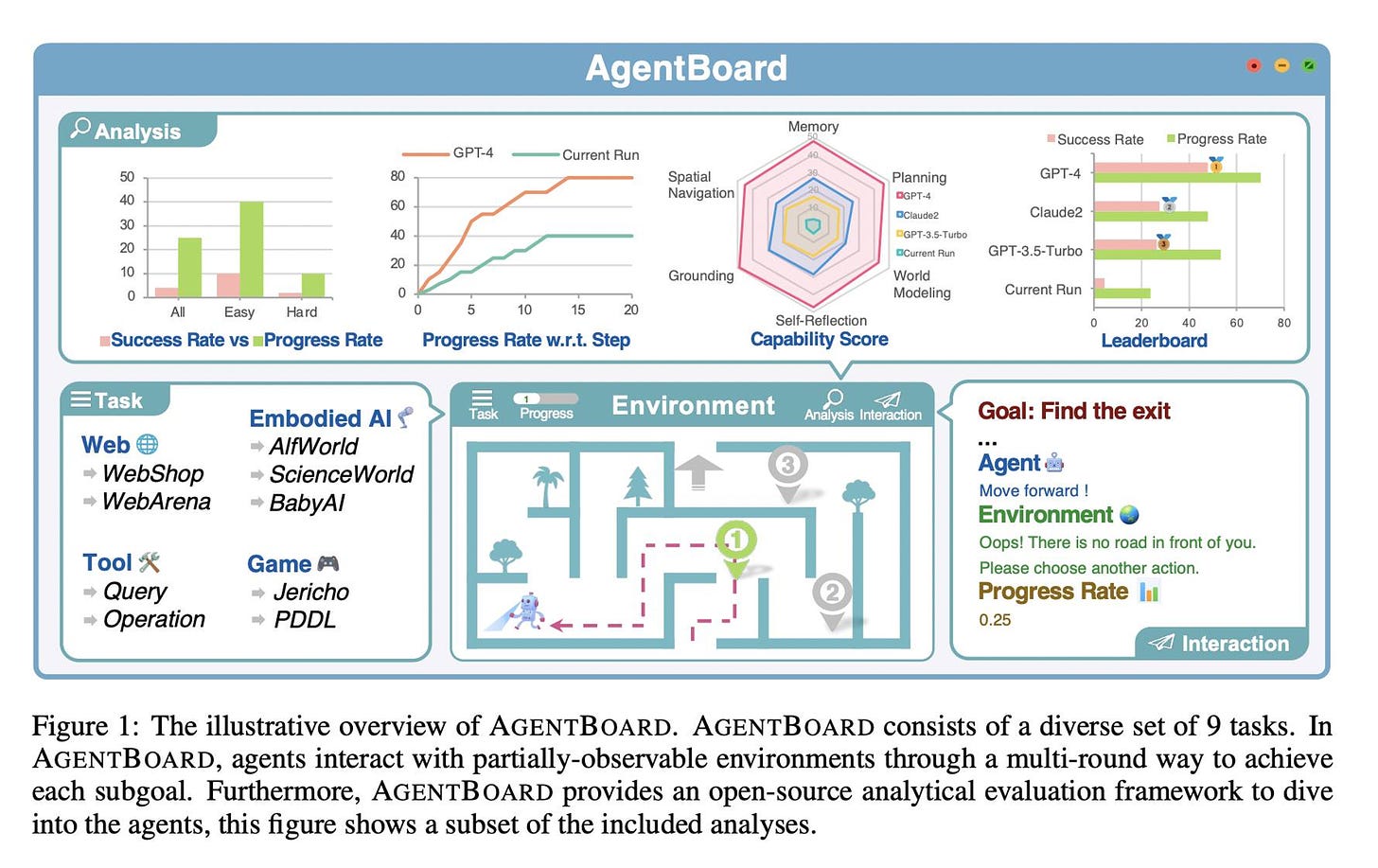
論文導讀這篇論文介紹了AGENTBOARD,一個創新的分析評估平台,旨在評估大型語言模型(LLM)作為通用代理的性能。AGENTBOARD通過提供一系列多元化的任務和環境,挑戰模型在多回合互動中的表現,特別強調了在部分可觀察環境中的操作。該平台不僅關注最終成功率,而且透過細緻的進度率指標和互動視覺化工具,深入分析模型在過程中的每一步表現,從而提供了對模型能力更全面的理解。 通用使用情境: 想象一下你在使用一款智能助手來完成日常任務,比如網上購物或遊戲。這個助手能夠理解你的指令,並在一系列的互動中逐步規劃並完成任務。AGENTBOARD就像是這樣一個測試場,它檢驗這個助手在未完全知曉環境(比如新的遊戲規則或網站佈局)的情況下,如何逐步學習並達成目標。 日常場景解釋 - A. ensuring multi-round interactions: - 日常場景: 像是和朋友玩棋盤遊戲,每一輪你都需要根據遊戲進展做出決策。 - 文章含義: 模型需要在多輪的互動中,根據之前的互動結果調整策略,模仿現實世界中的連續互動。 - B. partially-observable environments: - 日常場景: 駕駛在有霧的路上,只能看到有限的路段,需根據目前可見的情況做出行駛決策。 - 文章含義: 模型在不完全了解整個環境(比如不知道網頁上所有選項)的情況下,如何進行有效的探索和任務完成。