

如果你手上有數十篇文獻或訪談稿,必須在短時間內
✅ 快速鎖定核心主題
✅ 找出主題間的關鍵橋樑
✅ 決定哪幾篇資料值得優先深入分析
你會怎麼做?
有沒有可能,只靠一套流程,就能做到這三件事?
我最近就遇到一位在職碩士生小芳(匿名化處理,非真實本名),她有 30 篇文獻 + 一疊訪談逐字稿,準備下週要跟教授報告。
她每天晚上下班後,拼命在 Excel 裡標主題,標了幾百條句子,卻還是搞不清楚:
哪些主題是最多人提到的?
哪些句子同時跨了好幾個主題?
哪些訪談內容最有代表性、最值得先分析?
她不是不認真,只是:「資訊太多,時間太少」,她需要的不是更多的資料,而是一張清楚的地圖。
其實,這不只發生在小芳身上。
幾乎每一位做質性研究的研究者,或多或少都會遇到這三種困境:
❓ 研究常見三大痛點:
1️⃣ 主題一堆,卻看不出重點?
→ 編碼表裡主題代碼一大堆,卻沒有人告訴你哪幾個主題是整體的核心。
2️⃣ 句子踩兩條船,怎麼比對?
→ 有些語句同時涉及好幾個主題,人工比對超花時間,還常常漏掉橋樑主題。
3️⃣ 文獻或訪談資料太多,無從下手?
→ 總不能每篇都深讀吧?但又不敢漏掉關鍵資料。
✅ 我這週就針對這三個痛點,設計了一套 AI 協作解法:
🟡 對於「主題太多,看不出重點」的問題:
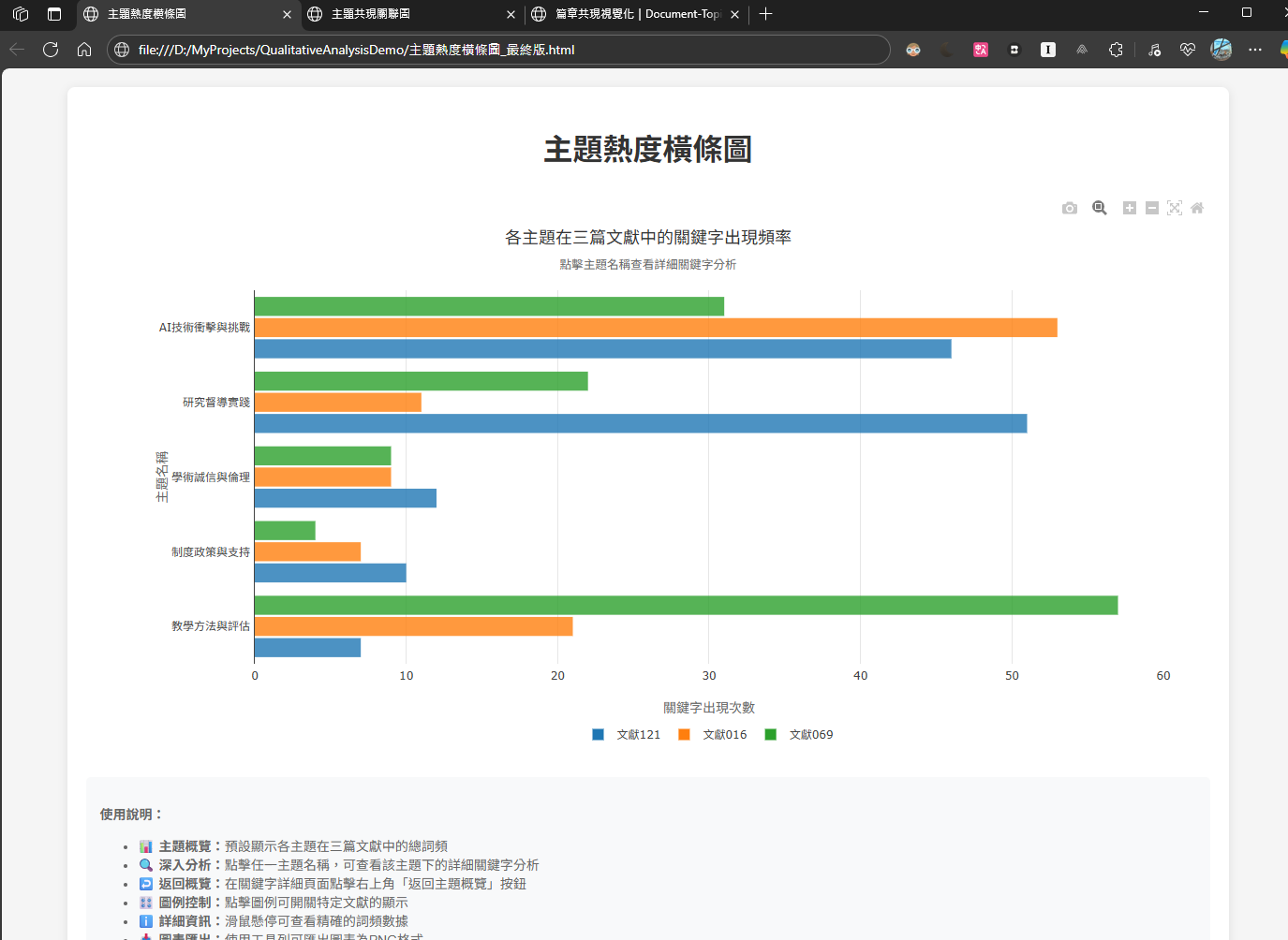
👉 我用「主題分佈長條圖」來視覺化主題出現頻率
👉 看圖就能知道哪幾個主題出現最頻繁、可能是核心主軸
🧠 _心法:用眼睛比用腦快,視覺化就是你的策略地圖_
🟡 對於「句子踩兩條船」的問題:
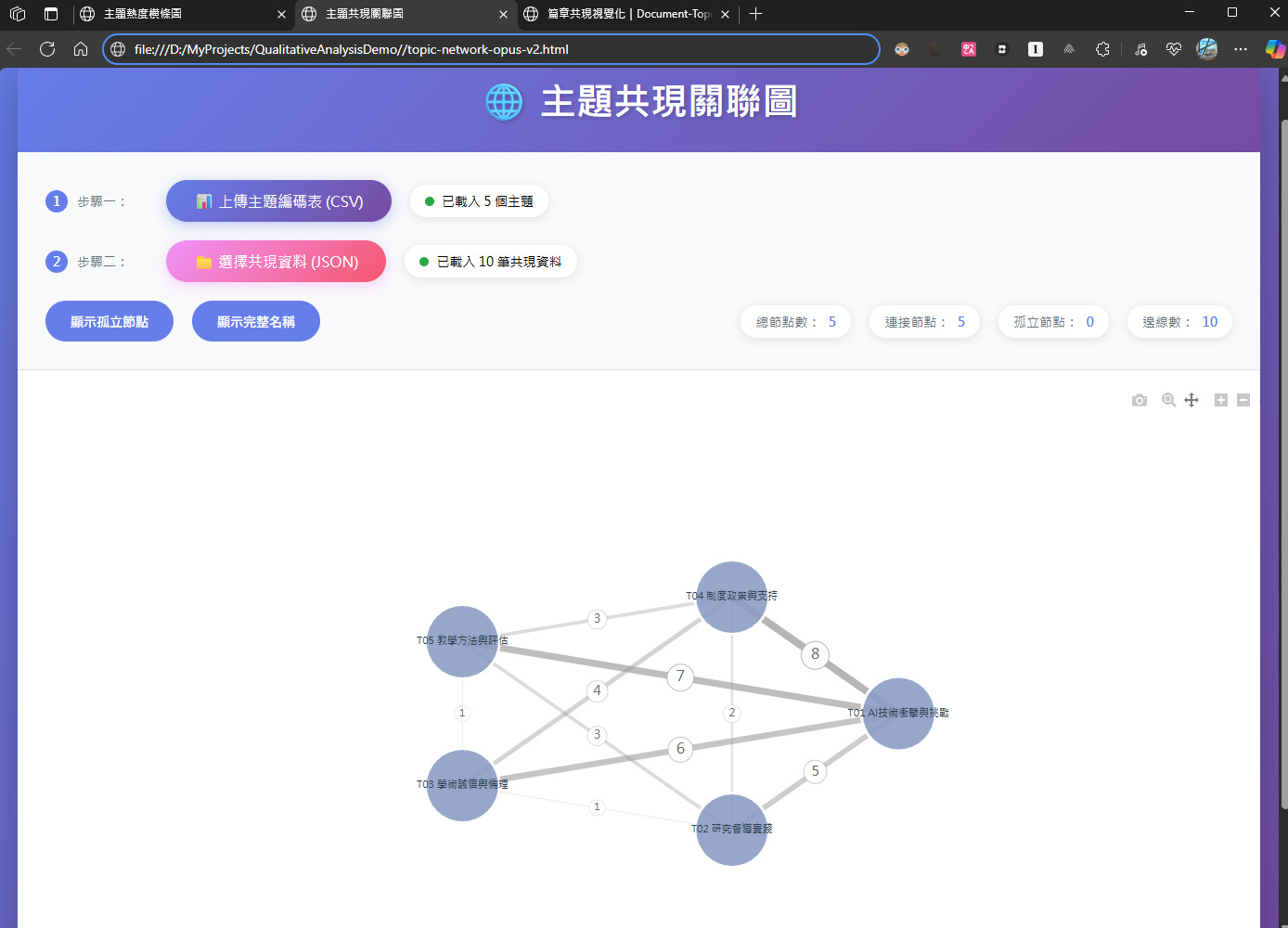
👉 我統計語句中多主題同現的情況
👉 用「主題共現關聯圖(Network Graph)」畫出主題之間的關係強度
👉 線越粗表示主題越常同時出現,一眼看出橋樑主題
🧠 _心法:主題不是靜態分類,而是彼此連動的脈絡網_
🟡 對於「不知道先讀哪篇文獻/訪談稿」的問題:
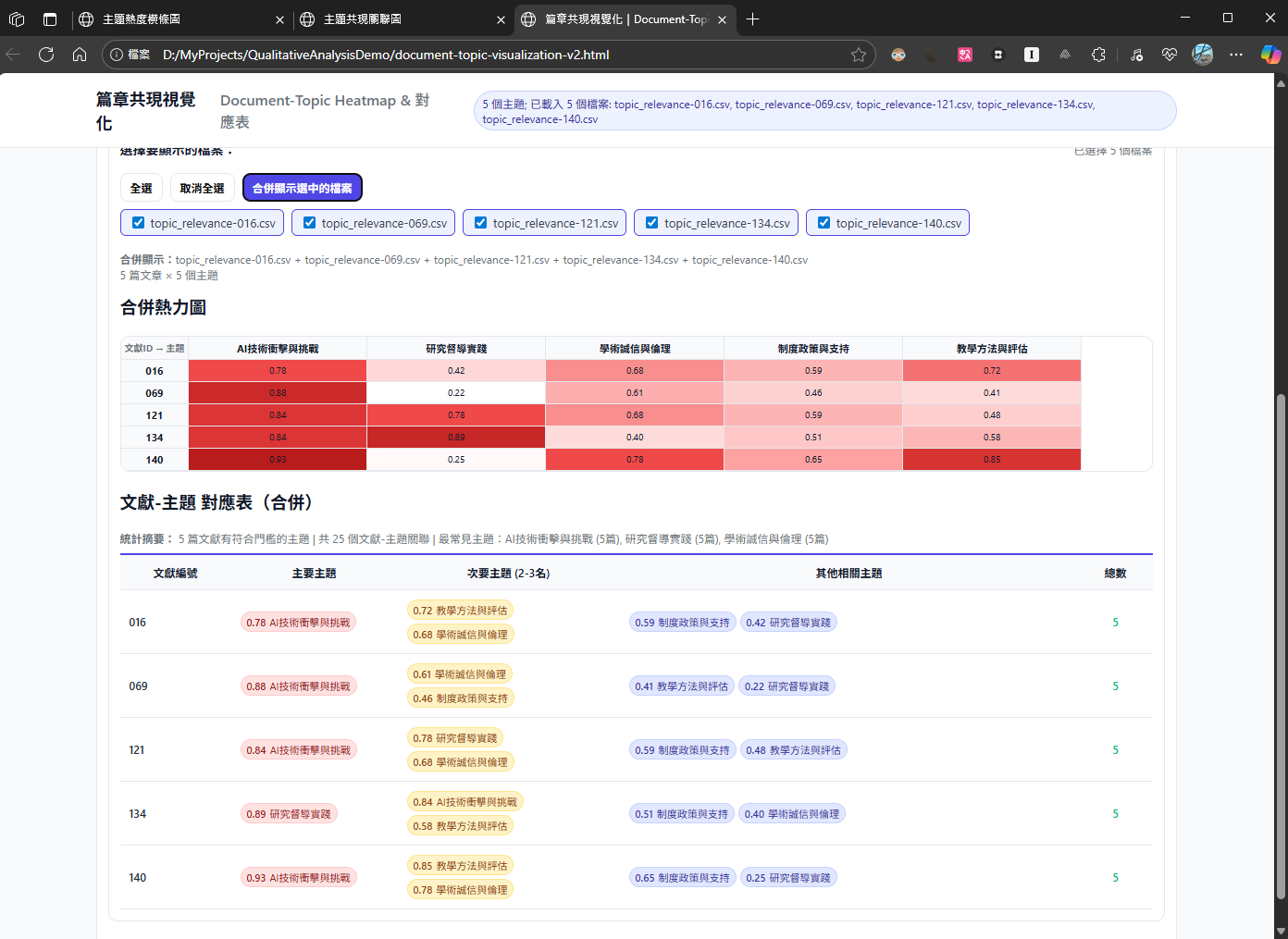
👉 我用「篇章 × 主題熱力圖」分析每篇資料涉及哪些主題
👉 顏色越深表示主題關聯越強,一秒找到前三篇「最值得深讀」的資料
🧠 _心法:不是樣樣都讀,而是挑對地方先讀_
🎯 這三張圖,不只是分析成果的展示,而是建立研究判斷的資料流程工具。
你不再是靠直覺選資料,而是用結構化資料 + AI 協作建立策略視角。
💬 那你可能會好奇:這些圖為什麼能跑得又快又準?
秘密不在工具,而在於「一開始的資料設計」——
我們預先定義好讓 AI 看得懂的資料結構(不是表格整齊,而是邏輯明確)。
例如:
我們會標記句子對應到哪些主題,像這樣:
「學生常用 ChatGPT 完成作業」 → T01, T03
「教授擔心 AI 工具影響誠信教育」 → T01, T04
這樣的語句 × 主題清單,就是後面「主題共現圖」的基礎。
🔁 我們把整個分析流程拆解成 6 段小步驟(Data Pipeline):
收集資料
切句
主題標記
統計出現頻率與共現
視覺化
回到資料,做出研究判斷
每一段資料都有明確目的,AI 才能幫得上忙。
🤖 那 AI 寫程式是怎麼進來的?
我們不是自己寫程式,而是用像 Claude Code 這樣的工具,
對 AI 說明資料格式與任務目標,就能讓它幫我們自動生成互動圖。
例如這樣說:
請幫我用 plotly.js 畫出主題共現關聯圖。
節點是主題,邊的粗細依共現次數調整。
資料來源是 co_occurrence.csv。
AI 就會幫你寫出整段可執行的互動圖程式,甚至還能加入說明文字。
🧠 所以整套流程的關鍵不是「會不會寫程式」,而是:
你能不能把資料整理成有邏輯的結構,讓 AI 能理解並幫你推論。
掌握這個思維,你就能在短時間內交出讓教授眼睛一亮的成果。
📌 如果你也正在做主題歸納、質性分析:
歡迎你看看我們正在打造的這套流程,
它或許能幫你省下反覆對著資料發呆的時間,
把心力集中在真正該思考的地方。
📣 我們近期將會公佈這項服務的細節,
如果你想要第一時間收到通知,可以先填寫這張「搶先關注表」👇
🔗 https://forms.gle/Ky8f5r2ALsy4fHVVA
🆘 如果你真的等不及,手邊已經有研究/報告急件需要協助,
也非常歡迎直接私訊我,我會盡力幫你搶救時間與品質。
🌱 重點不是讓 AI 取代你,而是幫你把心力放在「思考重點」上,而不是「找重點」上。